Entity-relationship (ER) modeling is a powerful technique for designing transaction processing systems in relational environments. By helping to automate the normalization of physical data structures, ER has greatly contributed to the phenomenal success of getting large amounts of data into relational databases. However, ER models do not contribute to the users' ability to query the data. I recommend a different technique (called dimension modeling [DM]) for structuring data for querying. Now that you have succeeded in getting the data in, it is time to get the data out.
There is no simple way to change an ER model into a dimensional model, even when you model the same data. The two approaches require different starting assumptions, techniques, and design trade-offs, and yield very different database designs. Dimensional modeling yields a database that is easier to navigate and query. A dimensional model also produces a database with fewer tables and keys to administer than an ER-designed database.
In the classes I teach to IS shops, I explicitly ask my students about their perceptions of ER modeling and normalization. They consistently say that they perform ER modeling "to take the redundancy out of the data." They look for one-to-many or many-to-many relationship among data elements, and separate the data elements into distinct tables joined by keys. They then use the ER tool to automate the creation of normalized physical data structures directly from the ER model. The use of normalized tables simplifies update and insert operations because changes to the data affect only single records in the underlying tables.
A dimensional model looks very different. Figure 1 shows a DM diagram for a typical business process: cash register sales in a large retail chain. We often call this kind of diagram a star join schema. The central table is called the fact table, and it is the largest table in the schema. It is the only one with a composite key. The rest of the fact table consists of "facts" that you can think of as numerical measurements of the business taken at the intersection of the dimensions. In an enterprise data warehouse, you can have a number of separate fact tables, each representing a different process within the organization, such as orders, inventory, shipments, and returns. These separate fact tables will be "threaded" by as many common dimension tables as possible. The surrounding tables are called dimension tables, and are much smaller than the fact table. Although the dimension tables have several descriptive text fields, they will always have far fewer rows and take up much less disk space than the fact table. Each dimension table has a single part key. The fields in dimension tables are typically textual and are used as the source of constraints and row headers in reports.
Star join schemas such as the one shown in Figure 1 support two specific kinds of queries: browse and multitable join. Browse queries operate on only one of the dimension tables and do not involve joins. A typical browse query occurs when the user asks for a pull-down list of all the brand names in the product dimension table, perhaps subject to constraints on other elements in the dimension table. This query must respond instantly because the user's full attention is on the screen. Multitable join queries occur after a series of browses and involve constraints placed on several of the dimension tables that are all joined to the fact table simultaneously. The goal is to fetch hundreds or possibly thousands of underlying records into a small answer set for the user, grouped together by one or more textual attributes selected from the dimension tables. Even so-called table scans fit this second paradigm, because there will always be some kind of constraint and some kind of grouping action in a decision-support query. This second kind of query is rarely instantaneous, because of the significant resources required to satisfy the query.
Dimensional modeling is a top-down design process. First you identify the main business processes that act as the sources of the fact tables, then you populate the fact tables with numeric, additive facts. You describe each fact record by as many business dimensions as you can identify. The resulting fact table records consist entirely of key values that have many-to-many relationships with one other, together with numeric data representing measurements of each dimension. Overall, the storage of the fact table records is quite efficient. The dimension tables represent the biggest departure from the usual ER and normalization techniques. It is important that the dimension tables remain as flat, single-level tables without being further normalized. This is the hardest design step for relational data modelers to accept.
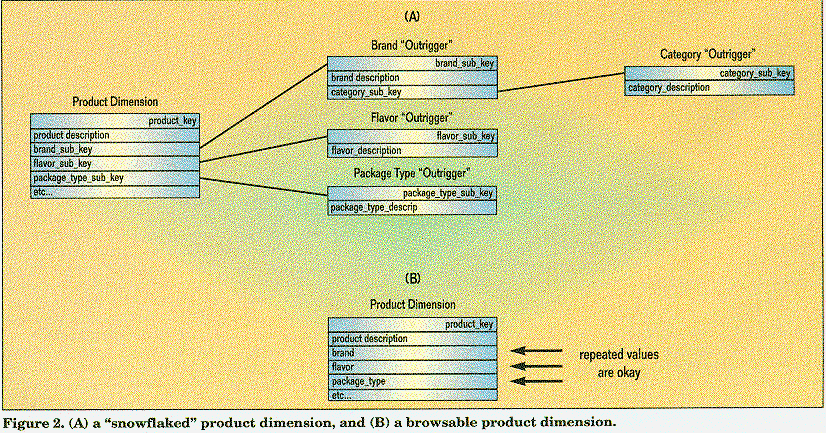
If the dimension tables are normalized into typical "snowflake" structures, as shown in Figure 2, two bad things happen. First, the data model becomes too complex to present to the user. Second, linking the elements among the various branches of the snowflake compromises browsing performance. Even when a long text string appears redundantly in the dimension table and can be moved to an "outrigger" table, you won't save enough disk space to justify moving it. The fact table is always overwhelmingly the largest table in a star join schema. In many cases, normalization can actually increase the storage requirements. If the cardinality of the repeated dimension data element is high (in other words, there are just a few duplications), the outrigger table may be nearly as big as the main dimension table. But we have introduced another key structure that is now repeated in both tables.
The final argument given for normalizing the dimensions is to improve update performance. This is rarely important in a decision-support environment. You update the dimension tables only once per night (typically), and the processing associated with loading perhaps millions of fact records dominates the really minor processing associated with inserting or updating dimension records.
A dimensional database design has a fixed structure that has no alternative join paths. This greatly simplifies the optimization and evaluation of queries on these schemas. There is only one basic evaluation approach, along with a "bail out" option. First, you evaluate the constraints on all of the dimension tables. Then you prepare a long sorted list of composite keys to the fact table. You scan the fact table composite index in sorted order once, fetching all of the required records into the answer set. Period. The only exception to scanning the fact table index occurs when you notice that your dimensional constraints are so weak that you have an unreasonably long list of composite candidate keys. "Unreasonably long" should be several times the number of actual records in the fact table. At this point -- and before attempting to scan the index -- you bail out to a relation scan in which you look at every fact table record without using any indexes.
Watch closely as your DBMS attempts to process a star join query. If the query evaluation plan has the fact table part way down the list with the dimension tables mentioned after it, your DBMS doesn't know how to do star joins. When the fact table is only part way down the list, the DBMS is writing a scratch subset of the fact table to the disk. The DBMS is then testing the resulting records individually against the remaining dimension tables and the result is a query that runs much too long.
A final and somewhat controversial difference between ER and DM is the degree of judgment left in the hands of the designer. The essence of a good dimensional model is the choice of the set of most natural dimensions from an end user's perspective. There are always two or more alternatives that represent the data in the same way, but package the dimensions differently. Ultimately, the designer's judgment must prevail.
It is helpful to have an ER analysis before embarking on a dimensional design because the data warehouse team will understand the data better. However, the team must set aside the ER diagram during the data warehouse design process because dimensional modeling must proceed from a user perspective, rather than from a data perspective. If you do not already have an ER analysis, I don't recommend taking the time to do it for the purpose of building a data warehouse database. The last 75 percent of an ER analysis is squeezing redundancy out of the data -- especially out of the dimension tables � which does not benefit the dimensional design.