
One of the most exciting new developments in data warehousing is the emergence of aggregate navigation, a capability that changes the architecture of all end-user applications. Aggregate navigation is a technique that enables DBAs to optimize performance by storing aggregate values in the database, without requiring end users to know about the existence of those aggregates. Several vendors offer aggregate navigation in their current products. In this article, I explain why aggregate navigation is so important, and look at how four vendors approached the issue.
The rapid growth of data warehousing has been accompanied by the creation of huge database of fine-grained detail. Increasingly, the trend has been to lay the foundation of the data warehouse with daily operational data or even transaction-level data. It is generally necessary to start at such a level, not because an executive or analyst will want to look at individual low-level records, but because the data must often be sliced very precisely. If you want see how many customers renewed their cable TV subscriptions each day following a particular media promotion, you need very fine-grained data.
Our data warehouse foundation layers consist of hundreds of millions of records in large fact tables, surrounded by a small set of six to eight dimension tables that serve as entry points into the fact tables. If database engines were infinitely fast, this design would be satisfactory, and we could concentrate on other issues such as application programming and front-end tools. However, we all know that we need to "cheat" and calculate some values in advance, such as totals, and store them in the database in order to improve performance. In our cable TV example, we would probably also be asking for the comparison of the renewal subscription rate against the monthly average renewal rate over the last year. If we use this baseline measure in our business often, we certainly do not want to process an entire year's worth of transactions every time we ask for this denominator. Every good DBA will build a set of aggregates to accelerate performance.
The building of aggregates is a huge double-edged sword in the big data warehouse environment. On the positive side, aggregates have a stunning effect on performance. The highest-level aggregates, such as yearly national sales totals, frequently offer a 1000-fold improvement in runtime, compared to processing the daily sales or the daily transactions. Other than ensuring that the database optimizer is working correctly, the addition of aggregates to a data warehouse is the most effective tool that the DBA can bring to bear on performance. But aggregates have two big negative impacts. First, they obviously take up space. If you build aggregates in three primary dimensions, such as product (brand level, category level, and department level), market (district level and region level), and time (week level, month level, and year level), these aggregates can multiply geometrically to overwhelm the database. A bizarre effect called "sparsity failure" can cause the number of aggregate records to exceed the number of base-level records, sometimes by a factor of four!
The second problem, and the one directly addressed by the aggregate navigators, is that an end user's query tool must specifically call for an aggregate in the SQL or it won't be used. This leaves the DBA with a nightmarish administrative challenge. If the end users' tools have to be hardcoded with knowledge of the aggregates, then the DBA doesn't have the flexibility to change the aggregate profile in the data warehouse. Aggregates can't be added or subtracted because all the end-user applications would have to be recoded. Until recently, DBAs responded to this problem by building every conceivable aggregate "for a rainy day," which leads to the over-proliferation of aggregates.
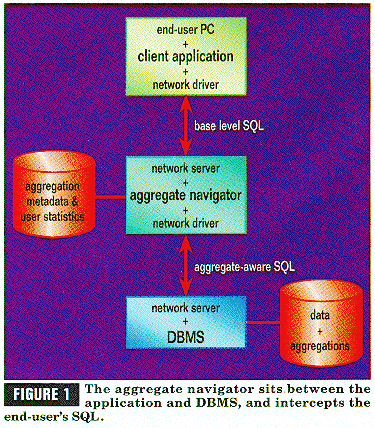
The aggregate navigator addresses the problem of hardcoded end-user applications by sitting between the end-user application and the DBMS, and intercepting the end user's SQL, as illustrated in Figure 1. With an aggregate navigator, the end-user application now speaks "base-level" SQL and never attempts to call for an aggregate directly. Using metadata describing the data warehouse's portfolio of aggregates, the aggregate navigator transforms the base-level SQL into "aggregate-aware" SQL. The end user and the application designer can now proceed to build and use applications, blissfully unaware of which aggregates are available. To tune system performance, the DBA can adjust the warehouse's portfolio of aggregates on a daily or weekly basis. This unhooks the dependence of end-user applications on the back-room physical aggregates.
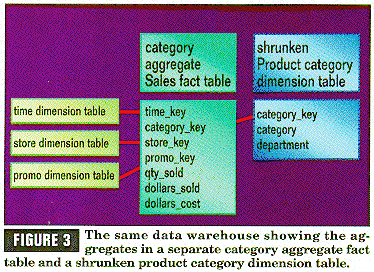
There are two main ways to store aggregates: in the original fact and dimension tables as extra records, or in separate fact and dimension tables as extra records. In both cases, you store exactly the same number of records; it is just a question of where to put them. The separate fact and dimension table approach is emerging as the recommended technique, even though it proliferates quite a few tables. The problem with storing the aggregates in the original fact and dimension tables is that, in order to distinguish the aggregate records from the base-level records, you must introduce a special LEVEL field in each of the affected dimensions. (See Figure 2.) This makes for rather complex table administration because now the dimension tables have several null entries for individual attributes that no longer make sense at the aggregated levels. The recommended technique is to take each kind of aggregate (such as product category by market region by month) and place it in a separate table. This "derivative" fact table is now joined to a set of shrunken dimension tables that contain only the attributes that make sense at the aggregate levels, as illustrated in Figure 3. Note that in going from Figure 2 to Figure 3, you lost the SKU and Package columns because they make sense only for the base-level data. They are not defined at the category level.
Two end-user tool vendors, MicroStrategy Inc. with DSS Agent and Information Advantage Inc. with Axsys, offer suites of query and reporting tools that navigate aggregates. Both of these vendors recommend and support the separate table approach for storing aggregates. Information Advantage also supports the LEVEL field approach for those customers already using it. Both of these tools embed the aggregate navigation in their tool suites in such a way that third-party tools cannot take advantage of aggregate navigation directly, although both vendors allow open access to all the metatables on the DBMS that describe the aggregate portfolio.
Two additional vendors, Hewlett-Packard (HP) Co. with Intelligent Warehouse, and Stanford Technology Group with MetaCube, offer aggregate navigation as a separate network resource that any ODBC-compliant end-user tool can use transparently. Both use the separate table approach for storing aggregates. HP deserves the credit for inventing aggregate navigation and for being the first to think through the client/server architecture for aggregates.
All of the aggregate navigators I've mentioned work only on dimensional data warehouses, which consist of large central fact tables filled with additive numeric facts, surrounded by smaller dimension tables filled with text-like values used for constraints and report breaks. The vendors also offer interesting statistics-collection capabilities for monitoring the user community's SQL and advising the DBA on which new aggregates to build. At present, none of these vendors offer integrated tools for actually building the aggregates. They are content to let the extract tool providers such as Prism Solutions Inc. (Sunnyvale, Calif.), Evolutionary Technologies Inc. (Austin, Texas), Carleton Corp. (Burlington, Mass.), and Vality Technology Inc. (Boston) manage the building of the aggregates in a separate phase.
In thinking about the approach these four vendors have taken, I believe that the future lies in network server-based aggregate navigators such as Intelligent Warehouse and MetaCube. The DBAs of the world will appreciate a solution that provides the aggregate navigation benefit transparently to all end-user tools. I suspect that the proprietary tool providers will find a way to unhitch their aggregate navigator modules from their tools and provide the capability as a networked, ODBC-compliant resource. Clearly, these vendors understand aggregate navigation. It will also be interesting to see how soon the big DBMS players notice this new development and add aggregate navigation to their bundles.
Without a doubt, I've omitted from this analysis one or more very deserving companies, and I will be called soon by their vice presidents of marketing. This new category of aggregate navigators is developing quickly and deserves a follow-up in this column in a few months. I will try to remain as even-handed as possible.