This month I look at some preconceptions about data warehouses that are not only false, but are dangerous to the success of your projects. By eliminating these preconceptions, you simplify the design of your data warehouse and reduce the implementation time. The first set of dangerous preconceptions concerns the operational data store (ODS).
Dangerous Preconceptions: The ODS is a data storage step before the data warehouse. The ODS is a convenient staging ground for raw data not yet ready for data warehouse consumption. The ODS is inherently unqueryable.
The Liberating Truth: The ODS must be the bedrock of the data warehouse itself. When data is extracted from the primary legacy systems, you must store it for safekeeping and for querying before you perform any summarization. It is this nonsummarized, queryable, and long-lasting form of the legacy data that is the ODS. Let' s examine the implications of these statements.
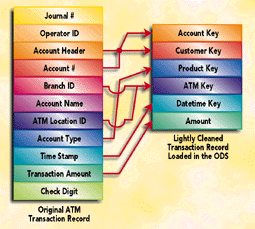
When the data is nonsummarized, it is a direct image of the original legacy base-level records. The charm of capturing this base-level data is that you can only roll the data upward; it is not possible to descend to a lower level. The data warehouse is "off the hook" if it makes the most granular data available.
Base-level records from legacy systems take on many different forms. Base-level data generally consists of transactions (operations performed against an "account") or a snapshot of the "account" taken at the end of the reporting interval (usually daily). In both cases, the base-level record looks remarkably similar. The record consists of key entries and textual and numerical measured values. These base-level records are almost always just one step away from being both dimensional and queryable. That one step consists simply of cleaning up the key values so that they point to clean dimensions. If a key value refers to a central, common business dimension such as customer, product, or geography, you should use a clean, corporatewide key value for the customer, product, or geography key in the base data that points to the respective dimension table recognizable by the other data sources in the data warehouse.
When base-level legacy records are subjected to this initial cleaning of the primary dimension keys, two wondrous things happen. First, the base-level records start to become queryable because they can be tied via a simple star join to the primary dimensions of the surrounding business. (See Figure 1.) Second, these records will be much easier to deal with in the future because some of the data processing needed to tie these records to other data in the data warehouse has already been done. In particular, it will not be necessary in the future to remember the funny, idiosyncratic customer, product, and geography codes in these particular records.
If this lightly cleaned base-level data is housed in an actual relational database, rather than being held in an intermediate "suspense file," then it really is queryable. With an aggregate navigator, this data can be accessed automatically whenever users ask precise questions that no higher level aggregate can satisfy.
The next set of dangerous preconceptions concerns a current hot topic: data marts.
Dangerous Preconceptions: The data mart is a quick and dirty data warehouse. You can bring up a data mart without going to the trouble of developing an overall architectural plan for the enterprise. It' s too much trouble to develop an overall architecture, and there is no way that you have the perspective to try that now.
The Liberating Truth: The data mart must not be a quick and dirty data warehouse; rather, it should be a single subject area implemented within the framework of an overall plan. A data mart can be loaded with data extracted directly from legacy sources. A data mart does not have to be downloaded formally from a larger centralized enterprise data warehouse.
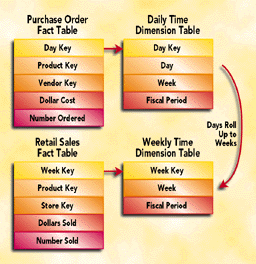
The key to a successful data mart strategy is simple. For any two data marts in an enterprise, the common dimensions must be conformed. Dimensions are conformed when they are the same or one is a strict rollup of another. Thus in a grocery store chain, if the "back door" purchase orders database is one data mart and the "front door" retail sales database is another data mart, the two data marts will form a coherent part of an overall enterprise data warehouse if their common dimensions (say, time and product) conform. The back door and front door time dimensions might both be at the individual day level. Or perhaps the back door time dimension is at the day level but the front door time dimension is at the week level. Because days roll up to weeks, the two time dimensions are conformed. The time dimensions would not be conformed if the back door time dimension was weeks and the front door time dimension was months - weeks don' t roll up into months - and the two data marts could not usefully coexist in the same application.
The beauty of conformed dimensions is that the two data marts don' t have to be on the same machine and don' t need to be created at the same time. Once both data marts are running, an over-arching application can request data simultaneously from both (in separate queries) and the answer set is likely to make sense. Logically, the only valid "row headers" in a joint report must come from common dimensions such as time and product in our grocery store example. But we have guaranteed that at least some of the row headers from these two data marts will be in common because the dimensions are conformed. Any of these common row headers can produce a valid report. (See Figure 2.)
The idea of developing an overall data warehouse architecture is daunting, but the key step in that architecture plan is simple: Identify the common dimensions. In virtually every company, the most important common dimensions are customers, products, geographies, and time frames.
Once the common dimensions have been identified, the development of separate data marts must be managed under this common dimensional framework. When two data marts use the same dimension (for example, customer), they must agree on a definition of "customer" at a very detailed level. Either the two customer lists must be identical, or one must roll up to the other.
The last set of dangerous preconceptions concerns dimensional models (star joins) and whether they are "robust."
Dangerous Preconceptions: The dimensional data model (the star join schema) is a specific high-level summary type of design that is not extensible and cannot readily accommodate changes in database design requirements.
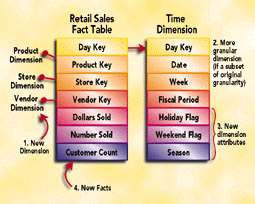
The Liberating Truth: The dimensional data model is extremely robust. It can withstand serious changes to the content of the database without requiring existing applications to be rewritten. New dimensions can be added to the design. Existing dimensions can be made more granular. New, unanticipated facts and dimensional attributes can also be added. (See Figure 3.)
The secret of an extensible star join database is building the fact table at a granular level. In Figure 3, the fact table represents daily sales of individual products in individual stores. Because all three primary dimensions (time, product, and store) are expressed in low-level atomic units, they can roll up to any conceivable grouping requested by a user in the future. To use the same example as in the previous section, if you have pre-aggregated the database up to weeks, you cannot provide reliable monthly data without returning to a primary database extract and building a new database incompatible with the old. With daily data, however, you can accommodate both the weekly view and the monthly view without compatibility problems and without re-extracting the original data.
Figure 3 shows how the star join schema provides standard, convenient hooks for extending the database to meet new requirements. All of the extensions shown can be implemented without changing any previous application. No SQL must be rewritten. No applications must be rolled over. This is the essence of extendibility.