SQL is very seductive. Simple SQL statements seem to read like English-language requests for information from a database. After all, almost anyone can figure out the intent of a simple SQL request such as this one that asks for the September sales of each of our products:
Select Product_Description, Sum(dollars)
-- all the columns in the final output
>From Product, Time, Sales
-- the tables needed in the query
Where Sales.Product_key = Product.Product_key
-- joining the Sales table to the Product table
And Sales.Time_key = Time.Time_key
-- joining the Sales table to the Time table
And Time.Month = 'September, 1997'
-- the "application" constraint
Group by Product_Description
-- the row header in the final output
Unfortunately, in most cases a more ambitious business request begins to make the SQL complex to write and read. For too long, query tool vendors did not venture far beyond the safe havens of simple SQL requests, like our example. In the early days, most query tools automated the construction of simple SQL requests, sometimes even showing the SQL clauses as they were being built. Only in the past two or three years have query tool vendors tackled how to issue the complex SQL needed for serious business questions. Some vendors, such as Speedware Corp. Inc., Business Objects Inc., and Brio Technology Inc. have deepened their tools by allowing the user to construct embedded subqueries. Some of these vendors as well as vendors such as MicroStrategy Inc. and Sagent Technology Inc. have also implemented multipass SQL where complex requests are broken into many separate queries whose results are combined after the database has completed processing all of them.
Are these approaches sufficient? Are we able to pose all the business questions we want? Are there some business results that beg to be recognized but are trapped in the database because we just can't "speak" clearly enough? Should the SQL language committee give us more power to ask difficult business questions, and could the database vendors implement these language extensions, all before the next millenium? (Only 935 days from the creation of this article!)
To get some perspective on these issues, let me propose seven categories of business questions. These are ordered from the most simple to the most complex, in terms of the logical complexity of isolating the exact records in the database needed to answer the question. This taxonomy isn't the only one possible for business questions or SQL queries, but it is useful as a scale to judge SQL and SQL-producing tools. As you read the following seven categories of queries, try to imagine whether SQL could pose such a query and whether your query tool could produce such SQL. The seven categories of queries are:
How did you do in comparing these business questions to SQL and to industry-standard tools? Not too well, I assume. Most query tools can really only do category 1 (simple constraints) easily. Nearly all the seasoned tools that I regularly write about in this column can also do category 2 (simple subqueries), although the user interface commands for doing these subqueries may be cumbersome. A few, such as Speedware, are aggressively selling their ability to perform category 3 queries (correlated subqueries). As far as I know, none of the standard query or reporting products has direct user interfaces for categories 4 through 7. If you are trying to support queries in these categories, you are faced with an architectural dilemma: These business questions are getting too complex to express in a single request. Not only should the user partition these queries into sequential processing steps in order to think more clearly about the problem, but the underlying algorithms may be more stable and controllable if they are doing less in each step. So how do you attack these difficult problems in categories 4 though 7, and can you use your current tools to get you part way or all the way to useful answers?
In my February 1997 DBMS column, "Features for Query Tools" (see page 12), I briefly described a technique for handling behavioral queries. Since then, I have been discussing this technique with many groups, and I am becoming convinced that this approach could be an important step forward for query tools that would extend their reach across categories 4, 5, and 6 (simple and derived behavioral queries and progressive subsetting queries). The technique partitions the problem into two steps:
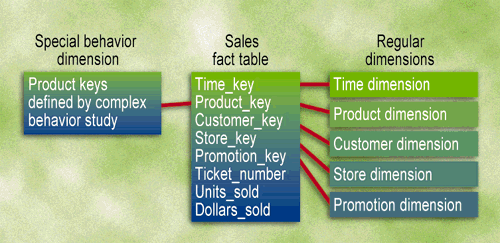
Like any design decision, this one involves certain compromises. First, this approach requires a user interface for capturing, creating, and administering real physical tables in the data warehouse. We can imagine building a simple applet in Visual Basic (or another capable application development tool) that sits outside of your favorite query tool or report writer. Whenever a complex exception report has been defined on the screen, you make sure that the appropriate set of keys are displayed and then capture them into the applet with cut and paste. This applet then creates the special behavior dimension table.
A second reality is that these tables must live in the same database space as the primary fact table because they are going to be joined to the fact table directly, thus affecting the DBA's responsibilities.
Third, the use of a random set of product keys, as in our example, will affect aggregate navigation on the product dimension. A sophisticated approach could build custom aggregations on the special behavior set for all those queries that summed over the whole set rather than enumerating the individual members. Aggregate navigation on all the other dimensions should be unaffected.
By storing the keys in the special behavior dimensions in sorted order, set operations of union, intersection, and set difference can be handled in a single pass, thus allowing us to construct derived behavior dimensions that are the combinations of two or more complex exception reports or series of queries.
Finally, by generalizing the behavior dimension to include a time key in each record along with the product key (in the example), the time key can be used to constrain records in the master fact table that occurred after the behaviorally defined event. In this way, we can search for behaviors in a sequential order.
This approach offers the hope that we can use our existing tools to extend our queries beyond simple constraints and subqueries. The Star Tracker freeware query tool, which I have distributed to more than 100,000 end users, contains the interfaces for creating and manipulating special behavior dimensions (called "studies" in Star Tracker). You could even use these tables with other query tools. On my home page (www.rkimball.com) you will see that the company "if..." has acquired the commercial rights for Star Tracker, and they have an upgraded version of Star Tracker freeware as well various commercial versions.
Next month I will tackle the seventh level of complex queries, which, as you may expect, require full-fledged data mining. Data mining is a big topic and the subject of October's column.