DBMS - November 1997

Preparing For Data Mining
Ralph Explains How to Transform your Data to Make It Ready for Mining.
Last month I wrote about an important set of data mining activities, which included clustering, classification, predicting, and affinity grouping (market basket analysis). (See "Digging into Data Mining," DBMS, October 1997) I hope I whetted your appetite and you are anxious to begin mining with one of the data mining tools you found on Larry Greenfield's Web page (pwp.starnetinc.com/larryg/index.html). But, are you ready? Does anything have to be done to your data, or can any data warehouse automatically be used for data mining? The answer is that often a significant amount of work needs to be done to prepare your data for data mining. In fact, you may spend more effort getting the data ready for data mining than you will spend actually doing the data mining. This month, I explore many of the data transformations you will need to perform.
Data Transformations for Data Warehouses in General
There is a set of basic data transformations you are probably already doing if you have a data warehouse. You are performing these transformations in your data extract system that pulls data from your legacy system, and you may be housing the data in your operational data store for cleaning and reformatting. You export the cleaned data from the operational data store into one or more of your subject-oriented data marts. Although there may be many transformation steps in your data extract system, the ones of particular interest to data mining are:
Resolving inconsistent legacy data formats, such as ASCII and EBCDIC, and resolving inconsistent data encoding, geographic spellings, abbreviations, and punctuation. I hope you are already cleaning your data at this level, because if you aren't, then you can't even ask for SQL groupings or produce simple reports with meaningful row and column headers.
Stripping out unwanted fields. Legacy data contains many fields that are meaningless from an analysis point of view, such as version numbers and formatted production keys. If you haven't stripped these out, the data mining tool may waste cycles trying to find patterns in these fields or trying to correlate these fields to real data. A data mining tool may interpret these fields as measurements or magnitudes, especially if the fields are numeric.
Interpreting codes into text. A classic form of data cleaning that should be done in all data warehouses is augmenting or replacing cryptic codes with textual equivalents written in recognizable words. These codes should already be in your dimension tables (not your fact tables) so that adding the explanatory text is an easy, graceful change to the dimension table.
Combining data such as customer data from multiple sources under a common key. I hope you have several rich sources of descriptions of your customers (or your products, or your locations) and you are merging these data sources under a common enterprisewide customer key in your operational data store.
Finding fields that have been used for several different purposes in your legacy data, where you must interpret the field's value based on the context of the legacy record. In some cases you may not even realize that you have a legacy field that is hiding multiple uses. Your data mining tool will almost certainly figure this out. Perhaps "go crazy" is a better description than "figure this out." A good way to find multiple used fields is to count and perhaps list all the distinct values residing in a field. My clients have been surprised many times by this exercise.
Data Transformations for All Forms of Data Mining
This group of data transformations may not be needed for standard reporting and analysis functions in a data warehouse but is required for just about every data mining application. Many of these transformations affect the numeric, additive facts in the central fact table of your dimensional data mart:
Flag normal, abnormal, out of bounds, or impossible facts. Marking measured facts with special flags may be extremely helpful. Some measured facts may be correct but highly unusual. Perhaps these facts are based on a small sample or a special circumstance. Other facts may be present in the data but must be regarded as impossible or unexplainable. For each of these circumstances, it is better to mark the data with a status flag so that it can be optionally constrained into or out of the analysis than it is to delete the unusual value. A good way to handle these cases is to create a special data status dimension for the fact record. You can use this dimension as a constraint and to describe the status of each fact. (See Figure 1)
Recognize random or noise values from context and mask out. A special case of the previous transformation is to recognize when the legacy system has supplied a random number rather than a real fact. This can happen when no value is meant to be delivered by the legacy system but a number left over in a buffer has been passed down to the data warehouse. When this case can be recognized, the random number should be replaced with a null value. See the next transformation.
Apply a uniform treatment to null values. Null values can often cause a data mining tool to hiccup. In many cases the null value is represented by a special value of what should be a legitimate fact. Perhaps the special value of -1 is understood to represent null. Null dates are often represented by some agreed upon date like January 1, 1900. I hope you haven't been using January 1, 2000. The first step in cleaning up nulls is to use a DBMS that represents nulls explicitly. Replace the specific data values with true nulls in the database. The second step is to use a data mining tool that has specific options for processing null data.
You may have an additional substantial complication if your fact table records contain date fields being used as foreign keys to date dimension tables. In this case you have no good way to represent null dates in your fact table record. You cannot use a null-valued foreign key in the fact table because null in SQL is never equal to itself. In other words, you cannot use a null value in a join between a fact table and a dimension table. What you should do is implement the join with an anonymous integer key and then have a special record in the dimension table to represent the null date.
Null values in data are tricky because philosophically there are at least two kinds of nulls. A null value in the data may mean that at the time of the measurement, the value literally did not exist and could not exist. In other words, any data value at all is wrong. Conversely, a null value in the data may mean that the measurement process failed to deliver the data, but the value certainly existed at some point. In this second case, you might argue that to use an estimate value would be better than to disqualify the fact record from the analysis. Some data mining professionals assign a most probable or median value in this case so that the rest of the fact table record can participate in the analysis. This could either be done in the original data by overwriting the null value with the estimated value, or it could be handled by a sophisticated data mining tool that knows how to process null data with various analysis options.
Flag fact records with changed status. A helpful data transformation is to add a special status indicator to a fact table record to show that the status of that account (or customer or product or location) has just changed or is about to change. The status indicator is implemented as a status dimension in the star join design. This status can be combined with the status developed in Figure 1. Useful statuses include New Customer, Customer Defaulted, Customer About to Cancel, or Changed Order. The Customer About to Cancel status is especially valuable because without this flag the only evidence that the customer canceled may be the absence of account records beginning the next billing period. Finding such an absence by noticing that records don't exist is impractical in most database applications.
Classify an individual record by one of its aggregates. In some cases it may be desirable to identify the sale of a very specific product, such as a garment in a particular color and size combination, by one of the garment's aggregates, such as its brand. Using the detailed color/size description in this case might generate so much output in the market basket report that the correlation of the clothing brand with say, a shoe style, would be hard to see. One of the goals of using an aggregate label in this way is to produce reporting buckets that are statistically significant.
Special Data Transformations Depending
on the Data Mining Tool
Divide data into training, test, and evaluation sets. Almost all data mining applications require that the raw input data be separated into three groups. Perhaps the data should be separated randomly into three control groups, or perhaps the data should be separated by time. The first data group is used for training the data mining tool. A clustering tool, a neural network tool, or a decision tree tool absorbs this first data set and establishes parameters from which future classifications and predictions can be made. The second data set is then used to test these parameters to see how well the model performs. An interesting problem that is discussed in Data Mining Techniques for Marketing, Sales, and Customer Support by Michael Berry and Gordon Linoff (John Wiley & Sons, 1997, ISBN 0-471-17980-9) occurs when the data mining tool has been trained too intensively on the first set. In this case the data is said to be "over-fitted" because it predicts results from the first data set too well and does poorly on the test data set. This is the reason to have a fresh second set of data for testing.
When the data mining tool has been properly tuned on the first and second data sets, it is then applied to the third evaluation data set, where the clusters, classifications, and predictions coming from the tool are to be trusted and used.
Adding computed fields as inputs or targets. A data mining exercise can be greatly leveraged by letting the data mining tool operate on computed values as well as on base data. For instance, a computed field such as profit or customer satisfaction that represents the value of a set of customer transactions may be required as a target for the data mining tool to pick out the best customers, or to pick out behavior that you want to encourage. You may not have to modify your base schemas with these computed values if you can present the data mining tool with a view containing these computed values. However, in other cases where the added information is too complicated to compute at query time in a view, then you have to add the values to the base data itself before you can perform data mining.
Map continuous values into ranges. Some data mining tools such as decision trees encourage you to "band" continuous values into discrete ranges. You may be able to do this by joining your fact table to a little "band values" dimension table, but this may be an expensive join against millions or billions of unindexed numeric facts. In such a case, you may have to add a textual bucket fact or even a bucket dimension to your fact table if the fact in question is important enough to be used as a frequent data mining target.
Normalize values between 0 and 1. Neural network data mining tools usually require that all numeric values be mapped into a range of zero to one. Berry and Linoff warn that you should make your data range a little larger than the observed data for this normalization calculation so that you can accommodate new values that fall outside the actual data you have on hand in your training set.
Convert from textual to numeric or numeral category. Some data mining tools may only operate on numeric input. In these cases, discrete text values need to be assigned codes. You should only do this process when the data mining tool is smart enough to treat such information categorically, and does not infer an ordering or a magnitude to these numbers that is unwarranted. For instance, you can convert most locations in the United States into a ZIP code. However, you can't compute on these ZIPs!
Emphasize the unusual case abnormally to drive recognition. Many times a data mining tool is used to describe and recognize unusual cases. Perhaps you are looking for fraud in a series of sales transactions. The problem is that your training set data may not contain enough instances of the target fraud behavior to extract meaningful predictive indicators. In this case you may have to artificially replicate or seed the training data with the desired target patterns in order to make the data mining tool create a useful set of parameters.
Writing this column was an eye-opener for me. I had not really appreciated the full extent of the data preparation that is required for full-fledged data mining. Although many of the data transformations I have described probably should be done in a general data warehouse environment, the demands of data mining really force the data cleaning issue. The purpose of data mining should be to discover meaningful patterns in your data, not to stumble over data cleanliness problems.
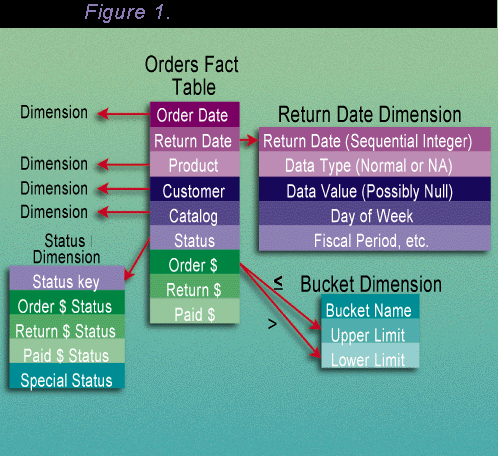
An Orders fact table with six dimensions and three facts showing design detail needed for data mining. The Return Data dimension must be joined with an integer, not a date. The Status dimension stores valuable flags for field and record status. The Bucket dimension allows dynamic value banding.
Ralph Kimball was coinventor of the Xerox Star workstation, the first commercial product to use mice, icons, and windows. He was vice president of applications at Metaphor Computer Systems and is the founder and former CEO of Red Brick Systems. He now works as an independent consultant designing large data warehouses. His book The Data Warehouse Toolkit: How to Design Dimensional Data Warehouses (Wiley, 1996) is now available. You can reach Ralph through his Web page at www.rkimball.com.
This is a copy of an article published @ http://www.dbmsmag.com/