
In the past year or two, data warehouses have become increasingly operational, increasingly fine-grained, and increasingly critical to day-to-day operations. In last month�s column (see "Relocating the ODS," DBMS, December 1997), I argued that the old, separate operational data store (ODS) must now be brought directly into the enterprise data warehouse. Another way to say this is that the enterprise data warehouse will sub-sume the needs of operational inquiries and reporting anyway. Let�s call this the operational data warehouse.
When you take an operational view of our data warehouse, you find that there are some characteristic structures that are probably independent of your specific kind of business. Virtually every operational data warehouse needs two separately modeled versions of the data: a transaction version and a periodic snapshot version. Furthermore, the snapshot version has an additional special feature called the current rolling snapshot. This current rolling snapshot is the echo of the formerly separate ODS. The current rolling snapshot is properly integrated into the overall enterprise data warehouse.
I hope that the most basic view of your operational system is at the individual transaction level. In some cases where we cannot get a proper transaction feed, we may have to construct pseudotransactions by examining the daily status of accounts and seeing what changed since yesterday.
In any case, the flow of low-level transactions is often quite easy to place into a good dimensional framework for querying in our data warehouse. For instance, the raw feed of ATM transactions in a retail bank environment contains the information needed to identify time, location, account, and transaction type. The extract process must convert the original legacy system identifiers into proper data warehouse keys that link to the respective data warehouse dimensions. This is basically a lookup process. The structure of the extracted ATM transaction would look like Figure 1.
You almost always add key-like information to the transaction fact record. You can add an audit key that points to a special dimension record created by the extract process. This audit dimension record can describe data lineage of the fact record, including the time of the extract, the source table, and the version of the software that ran the extract.
You may also include the original transaction record production identifiers, such as account number, so that you could open a terminal connection back to the transaction system and perform a direct online administrative operation.
You often can identify an Employee dimension associated with the transaction, like Teller, Customer Service Representative, or Cashier. Sometimes this information is carried in the original production data, but in other cases you may have to source the identification of the employee from a companion data source.
The fact record for an individual transaction frequently contains only a single "fact" that is the value of the transaction. In most cases you must simply label this fact Amount. Because there may be many kinds of transactions in the same table, you usually cannot label this fact with anything more specific.
The design of the transaction fact schema is not nearly as open-ended as the snapshot schema will turn out to be. We almost never need to add more numeric facts to a transaction schema because the transaction capture system usually returns just one amount in a transaction. More often you will add more transaction types to the transaction dimension, but this is not a schema change, rather this is a data content change.
Once you have built the transaction version of our operational data warehouse, you can perform many powerful analyses that cannot be done on any form of summarized data. Transaction level data lets you analyze behavior in extreme detail. Using the ATM example, you can perform behavior counts such as the number of times users of ATMs make mortgage payments at ATM locations not near their homes. You can perform exquisite time-of-day analyses such as the number of ATM transactions during the lunch hour or before work. Time-of-day analyses may allow you to do a fairly accurate queue analysis.
The gap between certain kinds of transactions is usually very interesting. In insurance companies one of the most important measures is the time gap between the original claim and first payment against that claim. This is a basic measure of the efficiency of the claims process.
Transaction detail also lets you look at sequential behavior. In the insurance example, you want to look at how many times you opened and closed the reserve against a claim, and whether there were any intervening changes in the claim made by the claimant. Interesting applications of sequential behavior analysis include fraud detection and cancellation warning. Banks are interested in predicting cancellation warnings because they would like to intercept the customer who is about to empty the account and ask them what is wrong or how the bank can better serve them.
Finally, transaction detail allows an analyst to do basket analysis. The obvious example is the retail environment where we ask what products naturally sell with a 12-ounce 7-Up. A less obvious example of basket analysis is to ask what additional satellite television channels we are likely to sign up for in the month following a purchase of a channel for football watching. A very tough version of basket analysis is to ask what didn�t sell in the market basket when we bought 7-Up. We might call this missing-basket analysis.
Having made a solid case for the charm of transaction-level detail, maybe you are thinking that all you need is a fast, big DBMS and your job is over. Unfortunately, even with a great transaction-level operational data warehouse, there is a whole class of urgent business questions that are impractical to answer using only transaction detail. These urgent business questions revolve around quick, accurate views of current status.
When the transactions are themselves little pieces of revenue, the boss can ask, "How much revenue did we take in?" by adding up the transactions. But in most businesses, there are many transactions that are not little pieces of revenue. Deposits and withdrawals in a bank are transactions, but they are not revenue. Payments in advance for subscriptions and for insurance coverage are even worse. Not only are they not revenue, but their effect must be spread out over many reporting periods as their organizations earn the revenue by providing the subscription or providing the insurance coverage. This complex relationship between individual transactions and the basic measures of revenue and profit often makes it impossible to please the boss quickly by crawling through individual transactions. Not only is such crawling time-consuming, but the logic required to interpret the effect of different kinds of transactions on revenue or profit may be horrendously complicated.
The answer to this dilemma is to create a second, separate fact table called the snapshot table that is a companion to the transaction table. The companion to our first example is shown in Figure 2. We add records to the snapshot table at the end of specific reporting time periods, often monthly. The application that creates the snapshot records must crawl the previous period�s transactions to calculate the correct current status that is the snapshot but at least this crawling only occurs once.
Often, I find it convenient to build the monthly snapshot incrementally by adding the effect of each day�s transactions to a current rolling snapshot. If you normally think of your data warehouse as storing 36 months of historical data in the snapshot table, then the current rolling month should be a 37th month. Ideally, when the last day of the month has been reached, the current rolling snapshot simply becomes the new regular month in the time series and a new current rolling snapshot is created the next day. The current rolling month is the leading breaking wave of the operational data warehouse.
The snapshot table is closely related to its companion transaction table. Usually the snapshot table is account-specific. In the snapshot you keep the Account and Time dimensions but suppress several of the other dimensions found in the transaction table. Location, Employee, and Transaction Type are all suppressed in Figure 2. You can keep the production identifier that refers to the account. You can keep an audit dimension, but the meaning of the audit key in this table is different and must refer to an aggregate status of the extract covering the entire reporting period. You can introduce a status dimension that flags this account in this time period according to various useful indicators like New Account, Regular Account, Account Under Scrutiny, and Account About To Close.
The fact structure in the snapshot table is much more interesting and open-ended than in the transaction table. You can introduce as many measures, counts, and summaries as you wish. All such facts must refer to the current period. Some of the facts will be completely additive across all the dimensions, such as Earned Revenue. Other facts will be semiadditive, such as Average Daily Balance. These particular semiadditive facts add across all the dimensions except time. Such semiadditive facts must averaged across time when used across time periods.
Because of the open-ended nature of the snapshot table design, we may progressively add more facts to this table as you understand our user�s needs in more detail. But obscure summaries are not worth putting in the snapshot table and must be computed from underlying transaction detail every time they are needed. Other basic measures like account balance absolutely must go in the snapshot table and are the reason for the table�s existence.
There may be times when you want a snapshot-like summary of a business at some intermediate point in time. It may make sense to start with the immediately preceding snapshot and add the effect of the incremental transactions between the beginning of that period and the desired date. This will be fairly straightforward if the measure you are interested in exists within the snapshot table. If the measure is more obscure (for example, the cumulative number of times a request for credit was denied) and is not part of the snapshot, then you may have no choice but to crawl that account�s transaction history from the beginning of time, because otherwise, you have no starting point.
Transactions and snapshots are the yin and yang of an operational data warehouse. Transactions give us the fullest possible view of detailed behavior, and snapshots allow you to measure the status of the enterprise quickly. You need them both because there is no simple way to combine these two contrasting perspectives. Used together, transactions and snapshots provide a full, immediate view of the business, and when they are part of the overall data warehouse, they blend gracefully into the larger views across time and across the other main dimensions.
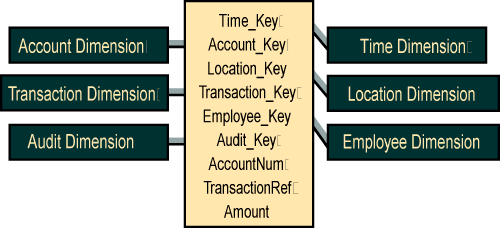
The transaction fact table and its associated dimension tables representing transactions at the ATMs.
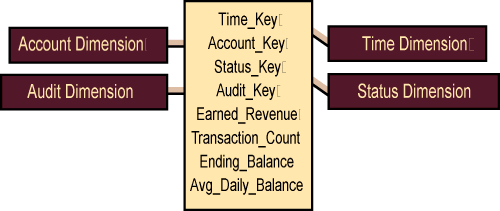
The snapshot table is a second, separate fact table that is a companion to the transaction table.