
It is easy in the data mart design business to get lulled into a kind of "additive complacency," where every data source looks like retail sales. In the simple world of retail sales all the transactions are little pieces of revenue that always add up across all the dimensions, and the dimensions themselves are tangible, physical things like Product, Store, and Date.
I frequently get asked, "Well, what about something like human resources? Most of the facts aren�t additive. Most of the facts aren�t even numbers, but they are clearly changing all the time, like numeric facts. How do I model that?" Actually, human resources data marts are a very good application for dimensional modeling. With a single design we can address just about all the major analysis and reporting needs. We just have to be careful about what is a dimension and what is a fact.
To frame the problem, let�s describe a typical human resources environment. We assume that we are the human resources department for a large enterprise with more than 100,000 employees. Each employee has a complex human resources profile with at least 100 attributes. These attributes include all the standard human resources descriptions including date of hire, job grade, salary, review dates, review outcomes, vacation entitlement, organization, education, address, insurance plan, and many others. In our large organization, there is a constant stream of transactions against this employee data. Employees are constantly being hired, transferred, promoted, and having their profiles adjusted in various ways.
In our design, we will address three fundamental kinds of queries run against this complex human resources data. In our first kind of query, we want to report summary statuses of the entire employee base on a regular (monthly) basis. In these summaries we want counts, instantaneous totals, and cumulative totals, including such things as number of employees, total salary paid during the month, cumulative salary paid this year, total and cumulative vacation days taken, vacation days accrued, number of new hires, and number of promotions. Our reporting system needs to be extremely flexible and accurate. We want these kinds of reports for all possible slices of the data, including time slices, organization slices, geographic slices, and any other slices supported in the data. Remember the basic tenet of dimensional modeling: If you want to be able to slice your data along a particular attribute, you simply need to make the attribute appear in a dimension table. By using the attribute as a row header (with SQL GROUP BY) you automatically "slice." We demand that this database support hundreds of different slicing combinations.
The hidden reporting challenge in this first kind of query is making sure that we pick up all the correct instantaneous and cumulative totals at the end of each month, even when there is no activity in a given employee�s record during that month. This prohibits us from merely looking through the transactions that occurred during the month.
In our second kind of query, we want to be able to profile the employee population at any precise instant in time, whether or not it is at the end of a month. We want to choose some exact date and time at any point in our organization�s history and ask how many employees we have and what their detailed profiles were on that date. This query needs to be simple and fast. Again, we want to avoid sifting through a complex set of transactions in sequence to construct a snapshot for a particular date in the past.
Although in our first two queries we have argued that we cannot depend directly on the raw transaction history to give us a rapid response, in our third kind of query we demand that every employee transaction be represented distinctly. In this query, we want to see every action taken on a given employee, with the correct transaction sequence and the correct timing of each transaction. This detailed transaction history is the "fundamental truth" of the human resource data and should provide the answer to every possible detailed question, including questions not anticipated by the original team of data mart designers. The SQL for these unanticipated questions may be complex, but we are confident the data is there waiting to be analyzed.
In all three cases, we demand that the employee dimension is always a perfectly accurate depiction of the employee base for the instant in time specified by the query. It would be a huge mistake to run a report on a prior month with the current month�s employee profiles.
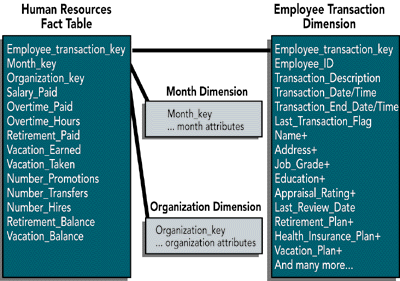
Now that we have this daunting set of requirements, how on earth can we satisfy all of them and keep the design simple? Amazingly, we can do it all with a single dimensional schema with just one fact table and a powerful dimension table called the Employee Transaction dimension. Take a moment to study Figure 1.
The human resources data mart consists of a fairly ordinary looking fact table with three dimensions: employee transaction, month, and organization. We show all three dimensions in Figure 1, although we only explode the employee transaction table in detail because that is the interesting part of the design. The month table contains the usual descriptors for the corporate calendar, at the grain of the individual month. The organization dimension contains a description of the organization that the employee belongs to at the close of the relevant month.
The employee transaction dimension table contains a complete snapshot of the employee record for each individual employee transaction. The employee transaction key is an artificial key made during the extraction process, and should be a sequentially assigned integer, starting with 1. Resist the urge to make this a smart key consisting of employee ID, transaction code, and effective date/time. All these attributes are valuable, but they are simply attributes in the employee transaction record, where they participate in queries and constraints like all the other attributes.
The employee ID is the normal human resources "EMP ID" that is used in the production system. The transaction description refers to the transaction that created this particular record, such as Promotion or Address Change. The transaction date/time is the exact date and time of the transaction. We assume that these date/times are sufficiently fine grained that they guarantee uniqueness of the transaction record for a given employee. Therefore, the true underlying key for this dimension table is employee ID plus transaction date/time.
A crucial piece of the design is the second date/time entry: transaction end date/time. This date/time is exactly equal to the date/time of the next transaction to occur on this employee record, whenever that may be. In this way, these two date/times in each record define a span of time during which the employee description is exactly correct. The two date/times can be one second apart (if a rapid sequence of transactions is being processed against an employee profile), or the two date/times can be many months apart.
The current last transaction made against an employee profile is identified by the Last Transaction Flag being set to True. This approach allows the most current or final status of any employee to be quickly retrieved. If a new transaction for that employee needs to be entered, the flag in this particular record needs to be set to False. I never said that we don�t update records in the data warehouse. The transaction end date/time in the most current transaction record can be set to an arbitrary time in the future.
Some of you may object to the storage overhead of this design. Even in a pretty large organization, this approach doesn�t lead to ridiculous storage demands. Assume we have 100,000 employees and that we perform 10 human resources transactions on them each year. Assume further that we have a relatively verbose 2,000-byte employee profile in the employee transaction record. Five years worth of data adds up to 5 X 100,000 X 10 X 2,000 bytes, or just 10GB of raw data. If your definition of employee transaction is much more fine grained so that a job promotion requires dozens of tiny low-level transactions, then you might consider creating a small set of super transactions like Job Promotion in order to make the data sizing realistic. Admittedly, this makes the extraction task more complex.
This compact design satisfies our three categories of queries beautifully. The first kind of query for fast high-level counts and totals uses the fact table. All the facts in the fact table are additive across all the dimensions except for the facts labeled as balances. These balances, like all balances, are semiadditive and must be averaged across the time dimension after adding across the other dimensions. The fact table is also needed to present additive totals like salary earned and vacation days taken.
The particular employee transaction key used in a fact table record is the precise employee transaction key associated with the stroke of midnight on the last day of the reporting month. This guarantees that the month-end report is a correct depiction of all the employee profiles.
The second query is addressed by the employee transaction dimension table. You can make a time-based cut through the employee database by choosing a specific date and time and constraining this date and time to be equal to the transaction date/time and less than the transaction end date/time. This is guaranteed to return exactly one employee profile for each employee whose profile was in effect at the requested moment. The query can perform counts and constraints against all the records returned from these time constraints.
The third kind of query can use the same employee transaction dimension table to look in detail at the sequence of transactions against any given employee.
Some of you may be wondering if the employee transaction dimension table isn�t really a kind of fact table because it seems to have a time dimension. While technically this may be true, this employee transaction table mainly contains textual values and is certainly the primary source of constraints and row headers for query and report-writing tools. So it is proper to think of this table as a dimension table that serves as the entry point into the human resources data mart. The employee transaction table can be used with any fact table in any data mart that requires an employee dimension as long as the notion of employee key is extended to be the employee transaction key. This design is really an embellishment of the standard slowly changing dimension we routinely use when dimensions like Product change at unexpected intervals. The key idea that makes this human resources database fit into our familiar dimensional framework is making each dimension record an individual employee transaction and then tying these records to precise moments in time.