My involvement with highly scalable commercial computing dates back to the early 1990s, before there were any significant commercial applications that could take advantage of some of the scalable architectures fast becoming accepted today. Since then, I�ve spent many long days in meetings about hardware architectures and many long nights helping with hardware selection for all kinds of scalable business systems, including systems intended to support online transaction processing (OLTP) applications.
Although hardware vendors� technological directions have tended to converge lately, there are still some key differences that can dramatically influence the outcome and economics of a project. In this article, I�ll show how hardware selection can affect issues such as uptime, transaction response time, number of supportable concurrent users, throughput, application maintainability, project timeline, hardware and personnel budgets, and even technical feasibility. I�ll discuss the industry trends shaping the various scalable hardware technologies as they relate to these considerations, and I�ll offer some suggestions on the hardware selection and sizing process itself.
The industry has come a long way since the early days. Scalable hardware and software technology have improved immeasurably, although they are still far from where we�d all like them to be. The issue of scalability has gone from an unfamiliar, somewhat arcane concept to an acknowledged business necessity. (Unfortunately, it has lost much of its meaning in the transition from technical term to marketing buzzword.) Perhaps most important, enough of a body of experience has built up in the user community that businesses are increasingly able to take advantage of this technology�s unique capabilities for transaction processing applications as well as more "conventional" decision support.
Increased experience has helped users become smarter and more efficient about hardware selection. At the same time, vendors have had time to "turn the crank" a few times, refining their products� focus on OLTP users� business requirements. In many respects we have seen an architectural convergence � vendors� offerings have started to look more and more alike as a common set of user requirements have motivated the development of similar technological answers.
I consider the state of scalable computing technology today to be analogous in many respects to the state of automotive technology in the 1920s. Although there is certainly plenty of room left for innovations such as seat belts and automatic transmissions (NUMA, perhaps), an initial de facto consensus seems to have emerged as to the basic ways in which a good, useful OLTP platform can be put together.
This convergence has made hardware selection somewhat less of a minefield than it was a few years ago. There are still a number of issues that someone involved in scalable hardware selection and specification must understand, because these issues can impact the timeliness and life-cycle cost of a project and occasionally even its feasibility.
If I had to give the best hardware selection advice I could in only one sentence, it would be, "Focus on the differences among products that truly affect the feasibility or cost of the application." While this sounds like trite, "I could have told you that" advice, I find it is followed in surprisingly few cases. Let me emphasize the two key portions of that sentence that are least often followed:
Differences. Each vendor is trying to address the same business issues, which has caused some of the important differences among vendor offerings to disappear. This is most true for the aspects of a platform that support more "standard" applications, which on large scalable systems are predominantly decision support. However, even for OLTP applications (which are definitely still leading-edge on cluster and massively parallel processor [MPP] architectures), the industry has been evolving. At this point, there is enough maturity in the marketplace that a process that identifies and focuses on the key technical issues that do make a difference can be a more efficient approach than trying to evaluate an entire system.
Truly affect. When selecting a platform to support their applications, many customers focus on their hardware�s price/performance ratio. The fact is that platform selection can drive application life-cycle costs in other, potentially more significant ways than simple price performance.
Much of the tendency to focus on the wrong issues stems from a hardware-centric view of a computer system, in my opinion. An obvious observation is that the hardware exists for one reason only: to run the software and support the application. In short, it�s not the name on the box, it�s the software that�s in it.
In the sections that follow, I�ll discuss the hardware technology issues I�ve encountered that significantly influence project cost, timeline, and outcome, and I�ll discuss an effective capacity-planning process based on business application cost drivers.
In my opinion, one of the most important attributes of a scalable OLTP system is its operability. The ability to configure, administer, and perform day-to-day IS operations on a system effectively influences almost every meaningful aspect of an OLTP project: system reliability, number of users supported, application maintainability, project timeline, hardware budget, personnel budget, and so on. In the real world of changing project requirements, deadlines, OLTP uptime constraints, and administrators still climbing a steep learning curve, there is no time for endless iterations of the system configuration in order to get it right. It does no good to have hardware that is 20 percent more cost-effective in a theoretical or benchmark environment if these real-world considerations make it impossible to use that hardware more than 50 percent effectively � a figure, by the way, that is not at all out of the realm of real user experience.
For a given general architecture, most of the attributes that affect the operability of a scalable OLTP system are functions of operating system software rather than hardware � though, of course, operating system selection and hardware selection are linked. While there are some differences between vendors� offerings, it is possible to generalize operability considerations within an architecture family to a surprising degree.
Most operability issues stem from implementation details and general "cleanliness" of a vendor�s operating system implementation, so they vary from vendor to vendor and are difficult to enumerate. However, some issues do appear to be common among the various vendors, including:
Operability, unfortunately, can be difficult to evaluate without actual "seat time" on a system. It is often valuable to insist on having platform-selection personnel attend vendors� administration classes for the system in question; even if it requires the investment of a few thousand dollars per evaluated platform, it is highly cost-effective in terms of the impact on the project this information can have.
In terms of hardware architecture, the three established players are symmetric multiprocessors (SMPs), MPPs, and clusters. Much ink has been spilled over the years about these technologies, so I need not go into detail about their construction. Figure 1 is a qualitative chart of the scalability and maturity of these technologies in their current states and the direction of market trends. I use the term "maturity" to denote both operability and reliability, which typically develop concurrently as a technology moves off the bleeding edge and into the mainstream.
Operability and reliability are more related than they might appear at first glance. In practice, many of the reliability problems users experience with these systems occur because the configuration is not quite correct due to system complexity, lack of configuration management, and poor error reporting. It can be very difficult both to configure these systems correctly and to track down configuration problems when they do manifest themselves.
In the past five years, SMPs have become the workhorses of the industry. Every major hardware vendor now has SMPs in its lineup, and most have had SMPs for long enough that their operating systems are quite mature and scalable, even for network-heavy workloads such as Web service. SMP�s single-memory model is both its allure and its Achilles� heel: Software designed for single-processor architectures will work straight "out of the box" on an SMP; it may not scale, but at least it can share machine resources with other processes and achieve some sort of limited scalability that way. Even more desirable, today�s database engines are sophisticated enough that most client/server transaction-processing database applications will scale very well "as is" with a comparatively small amount of tuning, making an SMP an ideal drop-in replacement if a uniprocessor server becomes insufficient.
By virtue of ever-increasing processor and backplane speeds, the raw performance of SMPs for OLTP applications has been climbing steadily. In addition, progressive software refinements (typically redesigns to eliminate "hot" resources) are improving the scalability of SMP-based solutions.
Because of their single shared system image and their relative compatibility with uniprocessors, SMPs are also the most mature of the scalable environments. They put the least burden on system administration staff and create the least potential for mishaps. Their comparative simplicity also reduces the attention that must be paid to performance issues by both application developers and administrators. However, although SMP administrative packages are generally full-featured, many vendors have not quite finished developing some tools, such as those for volume management, which will greatly reduce administrative costs for very large or high transaction-volume databases. The problem is, as MPP and cluster vendors have always been quick to point out, that an SMP�s single physical memory creates a scalability bottleneck. This is a well-documented fact (although there is much dispute among vendors about when these problems occur) but what it is important to realize is that SMP scalability problems are almost always the result of contention for specific hot resources stored in shared memory rather than on the theoretical bandwidth limitations of the backplane itself. In other words, it is the implementation of the software or operating system, rather than the hardware, that creates these limitations. This realization is important for several reasons:
In sum, however, SMPs are widely implemented and for good reason. The maturity and drop-in scalability of an SMP make it an ideal platform for workloads that are small enough not to run into its limitations.
To grow beyond the scalability limits of the shared-memory model, most SMP vendors now provide the ability to "cluster" their machines together. A typical cluster is a small number of large symmetric multiprocessor servers ("nodes"), linked together by a fast network and running clustering extensions to the vendor�s SMP operating system and a cluster-enabled database server. In addition to improved scalability, most of these configurations support the capability for failover � one server can take over the workload of another machine in the cluster in the event of failure. Since they are in reality completely separate machines, the failed machine can then be serviced while processing continues on the first.
On the downside, one of the most important things to realize about a clustered architecture is that most database applications will not scale "out of the box" the way they will on an SMP. If users are building their own applications, they must be constructed specifically to scale in a clustered environment. Partitioning the application is nearly always required and is often very effective, although for extremely demanding environments it may be necessary to build the application using a TP monitor. Many commercial off-the-shelf IT applications can be modified (with adequate application vendor support) to scale to a useful degree in a cluster environment using a partitioning approach; adapting such an application to use a TP monitor is generally not a viable alternative.
A vendor�s cluster offering is typically a direct offshoot of its large-SMP offering and so brings with it all the single-node management tools that are applicable to a multinode environment (or at least, those that the vendor has had a chance to adapt for that environment). Still, a cluster is composed of multiple separate machines, which places a burden on administrative personnel � in addition to administering several separate large servers, there is also a complex and typically immature clustering infrastructure to operate. Since the number of nodes in a cluster is very limited, most vendors have not focused on creating a large amount of infrastructure for administering them all as a single system. However, the small number of nodes keeps the operational burden small enough that customers are successfully using the redundant nature of these systems to increase reliability substantially.
MPP is acknowledged as the way to get the best available scalability at a significant cost in operability. Instead of evolving as an "add-on" to high-end SMP servers, most MPP technology was developed separately as a large number of single-processor nodes, interconnected by a fast, scalable, reliable network. Most vendors are starting to support MPPs based on SMP nodes, which dramatically reduces the administrative burden and increases the scalability that is achievable in a practical, real-world operational environment. MPPs typically support failover in a manner similar to clusters; however, the increased component count and administrative complexity often negate the improved reliability that these features provide.
Unfortunately, MPP database server technology currently cannot significantly scale transaction-processing applications that are not specifically designed to take advantage of these systems. The distributed-memory environment of an MPP system greatly increases the overhead of transaction management, so extensive application partitioning is required to achieve scalability. In almost all cases, an application with the required level of partitioning can only be developed using a TP monitor. Unfortunately, most off-the-shelf applications are not constructed this way, and most are not sufficiently partitionable to allow scaling to a large number of MPP nodes.
It is important to realize that both hardware and software technology are making great strides toward addressing this problem. Most MPP vendors now support large SMP nodes, which permit less-partitionable applications to scale on these systems to approximately the same level as on equivalent cluster configurations. In addition, most database vendors are working on technology that manages transactions in an MPP environment much more efficiently.
Because they historically have taken different evolutionary paths, MPPs often do not inherit well-developed management tools from SMPs. However, the necessity of administering tens or hundreds of nodes instead of a handful has forced vendors to develop infrastructures to manage all the nodes in an MPP as a single system ("single-system image"). Although single-system image management tools are nowhere near perfect, they do make it possible (if not even remotely easy) to manage a high-end MPP system.
One very important industry trend is that, as indicated in Figure 1, cluster and MPP technologies are quite clearly on converging paths. MPP machines are beginning to support large SMP nodes, and their administrative infrastructure is improving constantly. Meanwhile, cluster vendors are increasing the number of nodes they support and are creating single-system image-management software. It is quite clear that, within a year or two, the only distinction between a cluster and an MPP machine will be the number of physical cabinets on the machine room floor � a matter of packaging, nothing more. Even now, the distinction is blurry enough that a "small" MPP system made of a handful of large SMP nodes can scale an off-the-shelf OLTP application at least as well as an equivalent clustered configuration. To reflect the fact that this distinction is disappearing, for the rest of this article I will refer to clusters and MPPs collectively as "loosely coupled" architectures.
Concurrently with this trend, database servers for loosely coupled systems are evolving to the point where they will begin to address the general OLTP scaling problem. As this technology matures, it will become possible to scale applications without partitioning on small, loosely coupled systems (what would now be called clusters) and use partitioning without TP monitors as a scalability strategy (and thus begin to scale off-the-shelf applications) on larger and larger systems.
Nonuniform memory access (NUMA) architectures, after a few false starts over the years, are enjoying something of a resurgence � in mindshare, at least. The allure of these architectures is compelling. They offer the software compatibility and single-system image administerability of an SMP with the scalability of the loosely coupled approach. This is accomplished by giving each processor (or small SMP) its own dedicated memory as in an MPP, but using an interconnect that allows each one to perform operations on other processors� memory as if it were its own (albeit more slowly).
Unfortunately, here�s the rub: Because of the underlying shared-memory computing model, NUMA architectures are just as subject to scalability problems from "hot" data structures in software as SMPs. As I�ve already discussed, these hot spots, rather than hardware limitations, are the underlying causes of most limitations in real-world solution scalability.
This does not necessarily mean that the new generation of NUMA architectures is doomed to go the way of earlier machines such as the KSR-1 from Kendall Square Research. The new NUMA architectures have three things going for them:
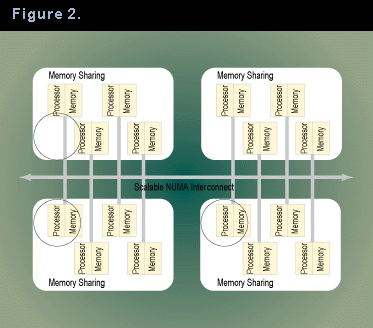
Although these refinements allow a NUMA architecture to approach the real-world scalability of SMPs, not much of the commercial software written to a shared-memory model would surpass an SMP in scalability when executed on a NUMA machine. In fact, initial implementations of commercial software on NUMA architectures look like Figure 2: The database software is configured to use small groups of processors as shared-memory systems, coupled loosely to other groups of processors using the NUMA interconnect as a more conventional networking medium.
Functionally, this is the same loosely coupled model used with conventional scalable architectures. So what is the advantage of NUMA? Here�s a major one: the system in Figure 2 is, at least in theory, a hybrid: At the same time the database engine is run in loosely coupled mode, nonscalability-critical components (such as most administrative functions) can be run as if the entire machine were one huge SMP. This could greatly reduce (but not eliminate) the technological distance to simultaneous scalability and administerability.
The bottom line: The jury is still out on NUMA. As with any new technology, the key to not getting burned is the ability to distinguish hype from reality. If NUMA vendors themselves can manage that and adopt a technology strategy in line with NUMA�s real capabilities, they might be in a position to lead the way to scalable, operable computing technology.
A few days ago, a colleague of mine who specializes in scalable mainframe systems was telling me a funny aside about some IS directors he had worked with. They deliberately overspecified their systems by 10 percent so that a few years down the road when the inevitable fiscal crunch came, they would easily be able to fulfill a 10-percent budget-cutting mandate. Besides the Dilbert-esque nature of the bureaucratic game being played, what struck me about the story was an underlying assumption about capacity planning: These people knew to within 10 percent what the capacity requirements of their systems would be. (It is impossible to overspecify your system by 10 percent if you don�t know the capacity requirements to within that margin of error.)
From what I�ve seen of the open systems world, at the time of most hardware purchases the eventual system requirements are known to some degree of confidence to within perhaps 50 percent. From the perspective of the project as a whole, this is not as precarious a practice as it sounds; the comparative low cost of modern hardware means that every MIPS and every spindle need not be judiciously allocated the way they had to be in the past. It is arguably cheaper to risk having to slap another processor or two in the server than to allocate many person-months worth of effort to developing a detailed capacity plan.
Still, going back to those holding the purse strings and asking for 30 percent more hardware budget is never a pleasant experience, and I have too much professional pride (not to mention a sense of obligation to spend my client�s money wisely) to specify an extremely large margin of error. In addition, the process of carefully designing a system helps ensure that I do not miss a critical scalability issue that might jeopardize the application. I do make it a policy to apply a certain amount of quantitative rigor to the capacity planning and system sizing process.
Over the span of the industry�s experience with scalable systems, several rules of thumb that give "SPECints per spindle" or "gigabytes per node" have come into common use for capacity planning purposes. Considering the simplistic view of system behavior and application load characteristics these rules embody, they can sometimes be surprisingly accurate. However, they have significant limitations, some of which are particularly relevant to transaction-processing applications:
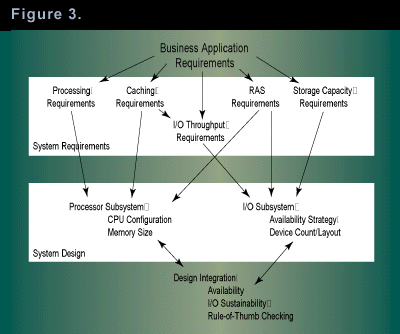
Rather than using these rules of thumb, I rely on a slightly more rigorous methodology such as that shown in Figure 3, which directly applies the specific requirements of the user�s application to the capacity planning problem. The process allows me the flexibility to stay at a reasonably coarse level of granularity and get a good approximation, with a confidence level that the system configuration is appropriate for this application; on the other hand, the method is rigorous enough to support a very extensive, detailed capacity plan.
The first step in developing the OLTP capacity plan is information-gathering. For a reasonably coarse-grained plan, we need sizing and create, read, update, and delete (CRUD) analysis (a structured analysis of operational workload) on the major application objects as well as the business issues motivating response-time, throughput, and uptime requirements. I typically find it useful to break these requirements out into the categories detailed in Figure 3.
Once the information is assembled in this organized fashion, it becomes relatively straightforward to distill the requirements into a configuration. This part of the method relies on the fact that almost all aspects of these systems are independently scalable, allowing each component to be sized to meet the requirements of the specific application. Of course, although this theoretical premise is largely accurate, it is not absolutely true � and this is where the method requires knowledge of the architecture and implementation limits of all aspects of the specific hardware and software to be used.
At the end of this process, the design integration step is a final, structured check on the feasibility of the derived system specification. We specifically check to make sure that the system as designed is capable of sustaining the scalability requirements dictated by the application. It is also here that we check our results against rules-of-thumb. This is simply a way of comparing our system design with the body of industry experience; if the system is extremely out of line with the norm, this should be explainable by a characteristic of the application that is similarly atypical.
One of the highly useful benefits of this process is that it quantifies the impact of various application requirements and components on the total system resource utilization. My experience is that for an OLTP application of any complexity there is always something surprising � you always end up saying, "Wow, I didn�t realize that operation was such a large fraction of the workload." This makes the sizing process an invaluable tool for focusing efforts to increase a system�s efficiency (thereby reducing hardware costs) or exploring what-if scenarios based on changing data volumes or user populations.
To reiterate one important point from earlier in the article, the way an OLTP application requirement moves through the capacity-planning and system-sizing processes (and eventually drives hardware configuration) is dependent on the way the software and operating system are designed to handle the workload. In this regard, I find it most useful to think of the software as driving the hardware selection and configuration, rather than vice versa.
As time has passed, the various scalable computer technologies have matured at their own pace and in their own way. It is important for the designers, implementers, and decision makers of scalable computer systems to be aware of the changing trends that shape the technology and determine the issues that will drive the outcome of today and tomorrow. At the highest level, however, the important things are what they�ve always been: one eye on the future, an understanding of the real issues, and a well-honed methodological approach to the application of technology to the business problem.
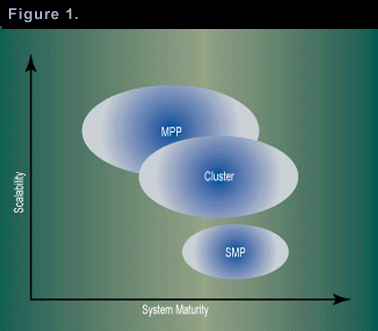
Figure 1.
Current technologies and trends.