
Object/Relational Grows Up
By W. Donald Frazer
Once upon a time, O/R databases were small. But now that they're growing, support for parallelism can address the challenges of VLDB complexity
Despite its many virtues, the relational data model is a poor fit for many types of data now common across the enterprise. In fact, object databases owe much of their existence to the inherent limitations of the relational model as reflected in the SQL2 standard. In recent years, a growing chorus of demands has arisen from application developers seeking more flexibility and functionality in the data model, as well as from system administrators asking for a common database technology managed by a common set of administrative tools. As a result, the relational model is now being extended by vendors and the SQL3 standard committees to include object capabilities.Object/relational (O/R) database products are still quite new, and the production databases to which they have been applied are usually modest in size--50GB or less. As O/R technology becomes more pervasive and memory and storage costs continue to fall, however, databases incorporating this new technology should grow to a size comparable to that of pure relational databases. Indeed, growth in the new technology is likely if for no other reason than that much of this new data is inherently larger than the record/field type data of traditional relational applications.
However, while limits to the growth of individual pure relational databases have been imposed as much by hardware evolution as by software, the limits for O/R databases will arise primarily from software. In this article, I'll explore the implications of the architecture approaches chosen by the principal O/R database product designers--IBM, Informix, NCR, Oracle, Sybase, and Computer Associates--for scalability of complex queries against very large collections of O/R data. The powerful new data type extension mechanisms in these products limit the ability of vendors to assume as much of the burden of VLDB complexity as they did for pure relational systems. Instead, these mechanisms impose important additional responsibilities on the designers of new types and methods, as well as on application designers and DBAs; these responsibilities become more crucial and complex as the size of the databases and the complexity of the queries grow. Finally, I'll explain how parallel execution is the key to the cost effectiveness--or even in some cases to the feasibility--of applications that exploit the new types and methods, just as with pure relational data. In contrast to the pure relational approach, however, achieving O/R parallelism is much more difficult.
I won't attempt to make product-by-product comparisons here. Thus far, no vendor is ready to take on the challenge of offering parallel execution in a production VLDB environment. You should be aware, however, that some architectural approaches have troublesome, but not necessarily fatal, limitations.
What Do We Mean by VLDB?
The term "VLDB" is overused; size is but one descriptive parameter of a database, and generally not the most important one for the issues I'll raise here. Most very large OLTP relational databases, for example, involve virtually none of these issues because high-volume OLTP queries are almost always short and touch few data and metadata items. In addition, these OLTP databases are frequently created and administered as collections of semi-independent smaller databases, partitioned by key value. In contrast, the VLDB issues discussed here arise in very large databases accessed by queries that individually touch large amounts of data and metadata and involve join operations, aggregations, and other operations touching large amounts of data and metadata. Such databases and applications today are usually found in data warehousing and data mining applications, among other places.The VLDB environments with these attributes are characterized by many I/O operations within a single query involving multiple complex SQL operators and frequently generating large intermediate result sets. Individual queries regularly cross any possible key partition boundary and involve data items widely dispersed throughout the database. For these reasons, such a database must normally be administered globally as a single entity. As a "stake in the ground," I'll focus on databases that are at least 250GB in size, are commonly accessed by complex queries, require online administration for reorganization, backup and recovery, and are regularly subject to bulk operations (such as insert, delete, and update) in single work-unit volumes of 25GB or more. For these databases, an MPP system, or possibly a very large SMP cluster, is required. However, many of the issues we raise will apply to smaller databases as well.
Parallel Execution of Individual Queries
In a pure relational database, success in such an environment of 250GB or more may require the highest degree of parallelism possible in execution of each individual query. The first key to parallel success is the structure of the SQL query language itself. In most queries, SQL acts as a set operator language that imposes few constraints on the order of execution; that is why relational database optimizers have so much flexibility in choosing parallel execution plans. Thus, SQL as an application language is extremely hospitable to parallel execution.Given this characterization, one must devise execution strategies that are optimized for parallel execution of an individual query, rather than merely providing for parallel execution of strategies optimized for serial execution. Note that individual DDL and DML operations--as well as other utilities such as backup and recovery--must execute in parallel. As indicated earlier, within the context of SQL2, RDBMS vendors did most of the work necessary to provide the necessary parallelism. Furthermore, it was possible to do so in ways that were largely transparent to the application developer and the DBA. They were greatly aided not only by the structure of SQL, but also by the fact that the core language and data types were mostly fixed during the '80s and early '90s, at least as insofar as they affect parallel execution. Even so, it takes a vendor at least two or three years to evolve a mature relational product that fully supports parallelism within a query for VLDBs.
It's worth noting that the complexity of adding parallelism for VLDB has two sources. The first is replacing serial algorithms with parallel ones. The second source is subtler: There is a qualitative change of mindset that must take place if one is to design competitive software for these very large collections of data. For example, the first reaction of a designer building a database load program is to make it use the INSERT function. This technique works for small- and medium-sized databases but not for giant ones; it is simply too slow. Instead, one must design for multiple streams of data to be loaded in parallel, capitalizing on the fact that multiple CPUs will be available on the MPP or SMP cluster. If the data is coming from a single serial source, such as a tape drive, the initial load task should focus only on getting each data item into memory as quickly as possible. The power of the other CPUs should then be invoked in parallel through tasks to get each datum to the right place, to index it properly, and so on.
These problems become more complex as O/R databases enter the mainstream; new and potentially exotic data types must be accommodated, and new methods must be written and optimized for parallel execution. Complex relationships far beyond the simple row and column structure of the relational model can and will exist among instances of the new data types and even among instances of current SQL data types--in a parts-explosion database, for example, or when a "purchase order" object view is superimposed on an existing on-order database. New data access methods to support the new operations and data types will also be required and must also be optimized for parallel execution. Finally, expect giant ratios of column sizes in O/R tables with the largest column entries being hundreds to thousands of times larger than the smallest columns within a table. This change will create a need for new approaches to storage and buffer management in servers as well as clients.
Hypothetical Financial Application
For an example, let's say that a simple financial database called Stockinfo contains information about various stocks. This database includes information about the closing prices for each stock on each trading day. Each database row corresponds to a separate stock, and the closing price information, P1, P2, Pm, is contained within a single column, Clprice, as a time series--a new data type. A query seeking attractive stocks for investment might take the following form: "Find all OTC listed stocks currently selling for less than $30, whose price/earnings ratio is less than 15, whose beta (volatility measure) over the last year is less than or equal to one, and which have increased in price by more than 10 percent within the past two months."SELECT FROM Stockinfo Candidate AS
Symbol, Industry, •PRICE (Clprice), Earnings,
•BETA (Clprice, 240), •%CHANGE (Clprice, 40)
WHERE Exchange = NASDAQ AND •PRICE (Clprice)<30 AND
•BETA (Clprice, 240)<=1 AND •PRICE (Clprice)/Earnings<15
AND •%CHANGE (Clprice, 40)>10%
Here, •BETA (S, n), •PRICE (S), and •%CHANGE (S, n) are all new methods applied to the time series S and computed on the last n elements where n=1 for •PRICE (S).
Because the database of stocks is very large, we need to execute this query in the most efficient manner possible. Ideally, all the computations implied should be performed on each row in parallel. In practice, however, the degree of parallel execution will be limited to the number of CPUs available and the efficiency of the software in invoking them.
Note that the Clprice column changes every trading day and is much larger than the other columns (Symbol, Name, Address, Exchange, Industry, and so on). This factor might call for storing the Clprice column entries separately from the rows to which they belong; RDBMS data buffering strategies do not work as well with very large column entries as they do with smaller ones, and it's usually even worse with a mixture of the two. In contrast, the WHERE clause contains a mix of standard and nonstandard SQL operators. If this is a common occurrence within the application framework for this database, local storage of the Clprice column make I/O operations more efficient.
Even in this simple case, it is clear that ORDBMS designers cannot cope with these issues on their own. There are no standard definitions of data types, no standard definitions of operators, a variety of individual column entries may cross multiple page boundaries, and there is no intrinsic knowledge of data size or volatility. Thus, unlike the case of pure relational data, optimization and parallelism for O/R become much more a shared responsibility among the ORDBMS vendor, extended data type and operator supplier, application developer, and DBA.
How are designers meeting these challenges? There are two distinct architectural approaches being taken by the established vendors to bring O/R capability to their relational products: federated and integrated.
Federated O/R architecture. The first architectural approach is conceptually the more straightforward and the easier to implement. As shown in Figure 1, in this approach a working RDBMS is positioned alongside an object database with extended data type capabilities, and the two are masked from the application program by a common software front end. In addition to the application program interface, this common software is responsible for overall execution and recovery management, query execution plan creation, and integration of the responses from the constituent databases to the (partial) queries it has posed on behalf of an application program query.
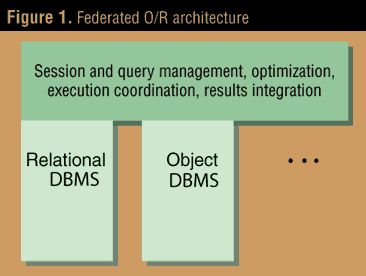
Unfortunately, the fewer such changes that are made, the greater the burden on the top software layer and the dimmer the prospects for optimal execution--which often requires exchange of intermediate results among the object and relational databases. Consider our stock-search query in such a setting. The checking of the Exchange, the Industry group, the Earnings, and possibly--if it contained a column with the Last price--the checking of the price and the computation of the P/E ratio could all be done in the relational database. The calculations involving beta and percentage change, however, fall most inevitably into the object database. Thus the top software layer must reconcile the two sets of partial results. The net result is to convert a simple (probably indexed) file scan into a join! The best that the relational database can do is return either all NASDAQ stocks or, with the additional Last price column, all NASDAQ stocks with a P/E<15 and Last price<30. The object database must return all stocks, regardless of exchange, meeting the Last price, beta, and percent price-change criteria.
The common front-end software assumes the responsibility for merging the two intermediate answer sets and creating the answer set to send back to the requesting application program. A clearly better solution in this simple case is to have the RDBMS qualify rows to the greatest degree possible, then pass requests for these rows to the ODBMS for final qualification. The added overhead here is that associated with the serialization of these two operations, including the messaging between the two DBMSs. The ORDBMS optimizer software must distinguish between these two approaches.
Let's take a moment to examine the parallelism so crucial to a VLDB. Each of the constituent databases must be optimized for parallel execution of a query if this architecture is to be competitive. Parallel technology is currently much more advanced in the relational design community than in the pure object database world, and it is possible to export much of it from the former to the latter if the object data model is restricted to tables of rows and columns, as is the case with O/R. However, such a modification to a functioning object database product is likely to be significant. In addition, the common software layer must also be capable of processing in parallel the large intermediate result sets returned to it for the overall architecture to succeed. This adds complexity and cost to the common layer beyond the initially simple functionality.
While not impossible to contemplate, the design of such a parallel common layer is certainly challenging. Historically, this architecture is similar to that of the original Sybase/NCR Navigation Server for parallel RDBMSs. This design was later replaced in the Sybase MPP product by one that provided for close coupling among the constituent (relational) databases for reasons such as those discussed here.
Note that under the optimistic scenario, both databases must be synchronized with Last price updates--a very simple example of the type of administration complexity issue driving the demand for O/R databases. Finally, by separating the object functionality from the relational, this architecture precludes the application of object functionality to legacy relational data. On the plus side, it keeps the highly optimized relational transaction software intact with minimal impact, and preserves its performance and isolation from object data processes. In addition, there's no question about where to store the Clprice column; it belongs in the object database component.
Integrated O/R architecture. As the name implies, this approach integrates object functionality closely with relational functionality within the same database software. The result is a close coupling of the two, with the potential to deliver powerful application enhancements, integrated administration of a single data store, VLDB parallelism, global performance optimization, and the availability of object functionality to legacy data. The price for all this functionality is a system design that is much more complex to implement and that exposes relational database application performance and data integrity to a risk that must be carefully managed during implementation as well as production.
There are several major product requirements for the successful implementation of an integrated O/R architecture, including new approaches to storage management, ability to add new methods to old and new operators (overloading), ability to add new indexing and access methods, new approaches to recovery, and--at least in the future--ability to multithread individual object methods. To understand the implications of these requirements, consider the execution path structure of a typical RDBMS product, as shown in Figure 2. The shaded portions of the execution path are those significantly affected by adding object capability to the RDBMS; the breadth of this impact offers insight into why implementation is so complex.

The optimizer must recognize and evaluate cost functions for the various operations proposed by the parser. In the O/R VLDB environment, these cost functions must often be more complex than the cost functions for SQL2 operations. The cost of evaluating the beta of a stock over more than 1,000 trading days, for example, is much different than the cost of evaluating it over 30 days. The optimizer must in general account for object size as well as number of objects. It must also consider caching strategy. Very large objects are frequently best funneled through memory rapidly, while traditional relational data can be kept around waiting for reuse in a data page buffer until the buffer is required for other purposes.
In another area, sequential dependencies among operators in SQL2 are well-understood, but those for new methods are not. Compression and encryption as methods applied to data, for example, must be performed in that order; these operations do not "commute" mathematically. Unless the encryption algorithm is very poor, encrypted data will not compress to any significant degree. Finally, the optimizer must account for the fact that execution of some methods on some objects may occur outside the database server, in an application server, or even in a client.
In an integrated architecture, execution management must allow for full parallel execution of relational and extended operators, indexing operations, and data access methods. Depending on the design of the RDBMS, adding this capability may imply a significant implementation change. Logging of object data is another area that often differs from that of traditional relational data. It would appear foolish to log the entire time series each day when a new entry is appended to Clprice, for example, or to log the entire row--including Clprice--when a quarterly earnings report causes the Earnings column to be updated. Thus, execution management must manage logging and provide new methods of recovery to manage cases in which (object) data is not logged.
Furthermore, at some point it will be necessary to support parallel methods. Consider a query seeking to evaluate the portfolios of a group of mutual funds to compare risks and rates of return. The evaluation of each individual fund is a complex operation that should be executed in parallel. Execution management must allow for this eventuality by providing for the parallel execution of multithreaded methods.
Storage and buffer management for an integrated O/R VLDB architecture must allow for parallel access by the ORDBMS processes and threads. It must also track where data is physically located, when large objects may be stored in a separate location (or even on different media) from the other data in a row. When required, it must also be prepared to materialize large objects in memory "just in time" for execution and return them, if modified, to storage.
Finally, although not in the mainline execution path, the DBA tools for an integrated O/R VLDB architecture must provide interfaces for submission and cataloging of new object type definitions, methods, index techniques, and access methods. In some cases, there may be a choice of methods or index techniques for a given object data type, depending on the characteristics of the particular object data in each database--long time series vs. short time series, for example. The DBA must also be provided with a set of interfaces to control the execution environment and the logging and caching of objects. Parallel administrative function execution is also a requirement for success in the O/R VLDB environment, just as in the RDBMS environment. Parallel creation of new index types--and parallel load, append, truncate, and dump, for example--should ideally work as well or better with object data as with traditional relational data.
New Responsibilities for All
Clearly, the extensibility and functionality that arises from extending object capabilities to the VLDB environment involve major new responsibilities for all parties in the delivery of successful applications.Definers of new data types and methods may no longer always be employees of the DBMS vendor, as was the case with pure relational data. If not, they will be responsible for providing optimization data and calculation functions for their cost estimates. They also must provide new indexing techniques and data access methods where required. Thorough testing of all this software--equivalent to that performed by DBMS vendors before product releases--will also be required, as will mechanisms for problem isolation and resolution. In the future they will also have to provide parallel versions of their methods where required.
Application developers have new responsibilities in this environment. They must think more carefully than ever about storage and buffer management and about what to log (and when). As for DBAs, they must implement storage and buffer management strategies as (ideally) guided by the application designer, formulate and implement a logging strategy consistent with data integrity and recoverability, make much more complex indexing and denormalization choices, and choose where to execute various functions for optimal cost effectiveness--in the database server, application server, or client.
Finally, the DBMS vendors also have new responsibilities for success. In addition to delivering a working and reliable O/R product for parallel environments, they must provide easy-to-use interfaces for all the ancillary functionality I've discussed here: defining and installing new data types, operators, indexing and access methods, optimizer cost functions, and so on. What's more, they must provide not only new application development tools, but new education and tools for testing the new functionalities in ways leading to application programs that are as reliable and powerful as today's relational applications (see Table 1).
Many of these comments apply not only to O/R VLDBs and applications, but to smaller ones as well. However, comparing the challenges in configuring, managing, and writing methods and applications for these database types is like comparing the operation of a supertanker to that of a ferryboat. There are similarities at the level of basic functionality, but many of the major issues arising in the giant systems are either absent or inconsequential in the smaller ones.
The most obvious differences arise from the fact that parallelism is an absolute necessity in the VLDB case, while it is optional--or possibly even detrimental because of overhead--for databases of more modest size. Other differences are associated with the complexity incurred by the sheer scale of metadata management, update operations, backup and restore operations, and so on. Finally, there is the complexity introduced by the need to expand the scope of optimization. This need goes beyond expanding the ways in which optimizers evaluate alternatives, which is principally a problem for ORDBMS designers. It includes the design of algorithms for new methods on very large collections of new data types, the design of cost functions to evaluate the efficiency of execution of these new methods, and investigation of what sequential restrictions apply to the execution of methods available to the optimizer. These issues are largely the responsibility of the method designer and implementer.
Combining the Architectures
A combination of the two architectural approaches I've discussed here may make excellent sense: A database of video clips might be joined to an integrated O/R VLDB via a common "federating" software front end, for example. This would permit the real-time software optimization required for smooth video retrieval and delivery to remain unburdened by query capability, while offering the benefits of a common application development and systems management environment for the two types of data. Queries involving content of the video library would be managed in this case by indices and other information--possibly including still frames of the videos--within the O/R VLDB.Glimpse of the Future
The coming world of O/R VLDB offers a wealth of opportunity to application developers and end users for applications that are more powerful, intuitive, and productive. As is frequently the case with new technology, however, a learning period will be required before such applications become routine. There is significant learning--and some significant implementation--yet to be done by the DBMS vendors to provide all of the DML, DDL, administration function, and training required to enable extended data types to enter mainstream production in O/R VLDB environments. There is, similarly, much learning and implementation necessary to provide all the data types and methods required, as well as the optimization data necessary to make them effective. Finally, application developers and systems administrators must extend their knowledge and vocabularies as they to learn to use these new data types and methods effectively in production VLDB applications. These processes should all be in full swing within a year, and should have begun to stabilize within one or two years thereafter.W. Donald Frazer is managing principal of the Frazer Group, a consulting firm based in Menlo Park, Calif. specializing in the design and deployment of large databases and wide-area digital networks. Dr. Frazer has been in the computer industry for more than 30 years, with a career spanning research, academia, hardware and software development, and executive management. You can reach him at [email protected].
| TABLE 1. Ten questions for your DBMS vendor. |
|
1. Do you optimize all operations for parallel or execute optimal serial plans in parallel? 2. Do you support optimizer choice of alternative methods for the same function on the same data type? 3. Does your optimizer account for object size and location? 4. Do you support parallel execution of multithreaded methods? 5. How much of query execution is parallelized automatically? 6. Does your "explanation" function offer guidance for improving parallel execution across new data types? 7. How do I administer your parallel ORDBMS? What functions can be carried out online? 8. Are backup and recovery parallel? Are they selective? Do they across storage media and data location (for example, including client and application server)? 9. Are all utilities fully parallel, including those for new data types? 10. Do you support views that include new data types and methods? What are their characteristics? |