
Sizing Up Parallel Architectures
Greg Pfister
Marketing collateral to the contrary, no known parallel computer architecture can do everything. SMP, clusters, and NUMA each bring different scalability, management, and availability issues to the table
Everyone would like to have his or her cake and eat it too, but that's impossible when choosing a parallel computer architecture. Parallel processing--that is, using multiple computing engines--can provide a broad range of
benefits, but no known parallel computer architecture does everything right. Furthermore, the decision to use a particular architecture can have long-term repercussions because your choice may end up embedded in application programs whose reimplementation for another
architecture can prove prohibitively expensive.
Salespeople, of course, can be relied on to avoid or downplay negative elements. Given normal sales psychology, they often genuinely
believe they have a solution that solves all problems. You'll want to
believe them; that's only human nature. Reality, however, is a mixed bag. To know which appropriately embarrassing questions to ask, you need more information.
In this article, I'll explain where the trade-offs lie among the three currently most prominent parallel architectures: symmetric multiprocessor (SMP), cluster, and ccNUMA (more commonly called NUMA), the acronym for the jawbreaker "cache-coherent nonuniform memory architecture." I'll focus on how the characteristics of the respective architectures affect system scalability under OLTP and decision support workloads, high availability, and system management.
A word of warning: This article spotlights the general characteristics of parallel computers. However, architecture is not destiny. A vendor, of course, must do things "right" and produce a good implementation of an architecture. Beyond that, it is possible for an implementation to have characteristics that are not inherent to the architecture. For example, traditional mainframe SMPs had (and have) features for high availability garden variety SMPs do not have. It clearly isn't impossible to do things an architecture doesn't naturally support, but doing so is swimming upstream--a difficult goal that sooner or later translates into being more costly than going with the flow.
THE THREE PARALLEL ARCHITECTURES
Hundreds of parallel architectures have been proposed and marketed over the years. While nearly all are now fond (or unpleasant) memories, two have withstood the test of time and will probably be with us for the foreseeable future: SMPs and clusters.
SMPs were introduced in the early 1970s and quickly became the de facto standard, the workhorse parallel architecture. If a hardware vendor supports any parallelism at all, it is likely to be the style of parallelism embodied by SMP.
Clusters were probably in use even earlier than SMPs. The cluster was born the first time a customer decided all the work wouldn't fit on one computer, or the work was important enough to require backup hardware. Only much later, however, was the idea dignified by a generally accepted name (Digital Equipment Corp. coined the term "cluster" in the mid-1980s) and formally supported by system vendors. Now clusters are a key card in the deck for virtually every Unix and Windows NT vendor.
The new kid on the block, having been developed in the early 1990s, is NUMA; only a few hardware vendors (Sequent Computers Inc., Data General Corp., Silicon Graphics Inc., and Hewlett-Packard, for example) and database vendors (Oracle and Informix, at press time) support it. Proponents claim that NUMA solves all the problems of other parallel architectures. In this claim they follow a long tradition: Anyone who's ever introduced a new parallel architecture argues that it solves all the old problems. Hype aside, as I'll explain later, there are technical reasons why NUMA may well be here to stay. Several major hardware vendors show signs of supporting it very soon.
SMPs
An SMP is a single computer with multiple equal processors, period. There are no multiple "anything elses"--no multiple memories, I/O systems, or operating systems. The word equal--as well as the word symmetric in the name--means that any processor can do what any other processor can do. All processors can access all memory, perform any I/O operation, interrupt other processors, and so on. That's what the hardware tells the software, anyway. In reality, the hardware continually "tells a lie" about one key aspect: There really are multiple memories in SMP.
As Figure 1 shows, in an SMP each processor has at least one cache memory (and probably several) that is its alone. Cache memories, or just caches, are necessary for good performance because main memory (DRAM) is way too slow to keep up with the processors, and it's falling further behind every year: It's already 20 to 40 times too slow, and in the near future will lag by a factor of hundreds. Caches (SRAM) are processor-fast but expensive, so they're relatively small. (Remember, you can never have your cake and eat it too.) Currently, caches are tens or hundreds of kilobytes in size, compared to tens or hundreds of megabytes in main memory. A cache is like a "work table" for the processor that holds currently used information; main memory is a big file cabinet across the room. Thus there are multiple memories in an SMP, but the software "expects" to see just one. Roughly, this implies that if processor Able says "store X in location Q" and, later, processor Baker says "load the value in Q," then Baker had better receive X. But if X were really put into Able's cache, how does Baker get it?
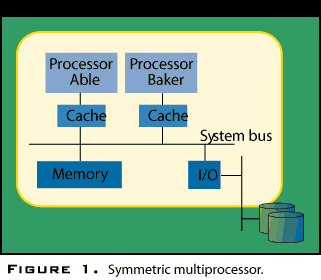
This example conveys the essence of the rather complicated lie told by the hardware known as cache coherence. When Baker asks for the Q value, assuming Q isn't in Baker's cache, the request for Q is broadcast throughout the computer, on the system bus, like shouting out in a room full of cubicles: "Who's got Q?" In response, everybody immediately starts looking for Q. All the caches, the memory, and even the I/O subsystem (if it's memory-mapped) check to see if they've got a recent copy for Q. Whoever has the most recent (meaning correct) value for Q sends it back to Baker. If Able recently stored X in its cache, then it sends X back to Baker.
There are three reasons that this "lie" is important: First, as we'll see later, it plays a major part in NUMA systems. Second, it has strong performance implications. And third, it is a major part of a key limitation of SMP: its lack of high availability.
One general performance implication is obvious: You go faster if you reuse data already in the cache--much faster, by factors of ten and twenty. Programs that go gallivanting all over memory are very slow; even if reorganizing the code for greater data reuse requires more instructions, they'll be much faster instructions.
However, there's another implication that relates to parallelism. The cache-to-cache transfer of data implicitly performed by SMP cache coherence is the fastest, lowest-overhead communication available in any general-purpose parallel architecture. Consequently, if your workload has lots of short transactions that must often synchronize on shared data--such as the debit/credit workloads characteristic of banking or account management--then an SMP is your best choice; no other architecture will work nearly as well. It also means that an SMP is the safest bet if you're not quite sure just how much synchronization you need to do, because it's sure to be worse than you expected.
This is not to say that cache-to-cache transfers are desirable; you always run faster in parallel if the separate parts of your parallel program communicate less. But if they must communicate often, they're better off doing it on an SMP.
Now let's consider availability. What happens if processor Able stores that value of Q in its cache and then drops dead? When Baker starts looking for Q, Able's cache can't respond. In that case, does Baker also drop dead, waiting forever for a response? Remember, there's still a location Q down in main memory. It has the wrong data, but the main memory hears the request like everybody else, and if a cache doesn't answer, it produces what it has. If there was no copy of Q in any cache anywhere, that was exactly the right thing to do. Unfortunately, in this case, the main memory delivers the wrong value. As a result, the entire SMP goes down on the account of a single processor. It can, and with many vendors' systems will, reboot and start up again with one fewer processor. But it will definitely go down.
This possibility is somewhat incongruous--after all, multiple processors are involved; it makes sense that the system goes into casters-up mode if the one memory or I/O system of an SMP dies. But can't the other processors keep going? No, they can't. One reason, as described earlier, is that of caches and cache coherence: the processors are too tightly coupled to keep running if one of them shuts down. Furthermore, the SMP is running one copy of the operating system, which means one copy of operating system data is shared by all processors. If a processor bites the dust, it will leave locks unlocked, data structures in partially updated states, and potentially, I/O devices in partially initialized states. Sooner or later (and it's always sooner) other processors will trip over locks that are never reset, follow bad pointers into oblivion, get wedged trying to work a device that's half fried, or otherwise get themselves into a pickle. The system becomes hors de combat in short order.
As you can see, the SMP architecture is not naturally highly available, meaning it can't be configured so that no one thing going wrong brings the system down. In other words, SMPs have single points of failure. Theoretically this problem can be fixed; realistically, it takes a lot of hardware, some significant cache complexity not discussed here, and a barrel of software. As a result, even mainframe vendors that used to employ SMP have gone to clusters, which naturally support high availability (more on this later).
Some vendors offer "hot-plug" processors, but they doesn't solve this problem. For example, ask the vendor what happens if you unplug a processor without first notifying the operating system; the answer will be along the lines of "Don't even think about doing that. Ever." Hot-pluggable processors are a good way to avoid some planned downtime--you don't have to take the system down to add processors, or, if you notice repeated transient errors on one processor, you can tell the system to take it offline and then unplug it. However, hot plug doesn't address unplanned errors.
NUMA
The easiest way to characterize a NUMA system is to imagine a big SMP. Now put on your safety goggles, grab a chainsaw, and cut it in half. Include memory and I/O in your bisection. Then reconnect the halves using a wire attached to the (severed) system busses. That's NUMA: a big SMP broken up into smaller SMPs that are easier to build (see Figure 2).
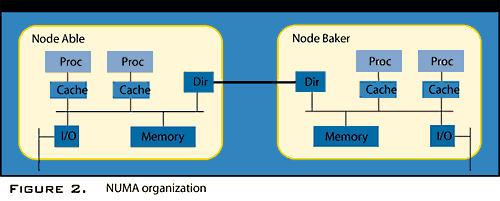
It's obviously not quite that trivial because the big deal in NUMA systems is that they're cache-coherent: The hardware tells the big lie that all those separate memories in all those separate units (usually called nodes) are really one giant memory. As you might imagine, this approach has a number of implications. First of all, this system has exactly one real address space over the entire machine (all the nodes). Real (not virtual) location 0 for every processor on every node is the one, singular, location 0 of the particular memory that sits in node 0. The whole machine's location 1 is location 1 in node 0, and so on until node 0's memory is used up. Then you go to node 2, then node 3, and so on. The pieces that implement this real address spaces are the boxes labeled "Dir" in Figure 2. (They do other things too, as I'll explain later.)
Suppose a processor on node Able tries to "load the value in Q" when Q is not in cache; it's only in memory. Furthermore, suppose Q's real address isn't in node Able. Here's the resulting sequence:
- As usual, the cache in node Able emits the "Who's got Q?" shout within its node.
- Everybody in Able, as usual, looks for Q, including Able's Dir.
- Able's Dir, seeing Q, realizes it's on node Baker and in effect says "Hold on a minute, I'll get it."
- Then Able's Dir sends a message to Baker's Dir asking for Q.
- Baker's Dir then acts just like a processor and shouts "Who's got Q?" over on node Baker.
- Baker's memory hears the shout and coughs up Q's value, which is then picked up by Baker's Dir and sent in a message back to Able's Dir, which finally sends the value to the processor that originally requested it.
As you might imagine, this process takes a bit longer than if Q were initially on Able's node. That's where "nonuniform memory access" comes in. The amount of time it takes to get a value is not, as in an SMP, the same regardless of the location and which processor asks for it (unless Q is in cache, of course). In NUMA, the amount of time needed to get a memory value varies--it's nonuniform--depending on where the location is (local to a node or remote in another node). In the taxonomy of parallel architectures that gave rise to the term NUMA, an SMP relies on "UMA": uniform memory access.
The key question is: How "nonuniform" is NUMA? For example, if it only takes 10 percent longer to get a value on another node, then trust me, nobody cares. Everybody will treat the system just like an (UMA) SMP and plain old SMP programs will run just fine. In fact, some have systems shipped in which it took 40 percent longer to reach the "other side." Nobody publicized it, and nobody cared.
The current crop of NUMA systems, however, use a network or ring to connect the nodes so you can have many of them; as many as 64 nodes, totaling 128 processors, in some systems. As a result, the current NUMAs don't take just 10 percent longer. In fact, the best of the current lot--Silicon Graphics' Origin2000 series--takes 200 percent to 300 percent longer. Sequent's NUMA-Q takes at least 750 percent longer, and even more under high load. While no value is measured or claimed for Data General's NUMALiiNE, it is, from my understanding of its structure, longer than that of NUMA-Q.
With, for example, a 750 percent difference, you really should care where the data is if you're interested in performance. The operating system can be (and has been, for NUMA vendors) modified so that, for example, when a program asks for a block of memory, the memory is allocated on the node where it's running, and when a processor looks for work, it looks first on its own node. Subsystems that do their own scheduling and memory allocation--including databases--have to be similarly modified (as Oracle and Informix have done). With a lower remote access penalty this modification isn't as necessary; Silicon Graphics claims that many SMP programs run well on its platforms without modification.
But that's not the end of the story. Remember, cache coherence has to work across nodes. If a processor in node Able modifies, in its cache, a value it got from node Baker, then when a processor back in Baker asks for that value, it has to be retrieved. To make this process work, the Dir box on Baker tracks who has received values from Baker in a directory (hence the term "Dir"). When Baker's processor emits the "Who's got Q?" shout, Baker's Dir box looks in its directory. If it finds a reference to Q, it in effect says "Hold on, somebody else has Q" and retrieves the value from Able using a sequence much like the one I described. Thus the basic semantics of SMP operation--loads and stores operating as if there were just one memory--are maintained. This process is the basis of NUMA vendor claims that their systems "maintain the SMP programming model."
Now let's discuss how long the cache-to-cache transfer takes. Main memory is slow, so the time to get a value from main memory has consistent, additional overhead whether the value is local or remote. Local is l1M and remote is r1M where M (memory access time) is rather large; the difference between the l and r values--the time to do local and remote operations--is diluted by that big M value. Caches, in contrast, are fast, so there's no location-independent added factor to hide behind. As a result, the numbers for doing cache-to-cache transfers across nodes are significantly worse than the ones we've discussed thus far.
How much worse? Well, nobody's talking about that--at least not in public. I would estimate that the remote access penalty for cache-to-cache transfers is, conservatively, at least twice that of the main memory access penalty: 400, 600, 1500 percent, or even worse. As a result, NUMA systems are unlikely to match SMPs for workloads where tight synchronization is required. You're much better off, in fact, if the workload can be partitioned--broken into parts that run on each NUMA node and communicate relatively infrequently. For example, this partitioning could occur if you're keeping the accounts of both the East Coast and West Coast offices on the same machine. East Coast operations usually don't affect West Coast operations and vice versa, and setting up the database so they're separate will result in a system that runs well on a two-node system.
Another useful partitionable case is that of business intelligence: decision support, OLAP, ad hoc queries, and the like. In these cases, there are well-known and commonly deployed automatic partitioning methods that all competent database systems use to break large queries into parts that run independently--for example, for scanning a huge table by separately scanning parts of the table. (Joins can be partitioned too, but it's more complex.) In fact, NUMA systems run business intelligence applications quite successfully. Those applications can be partitioned with minimal grief and usually don't have a severe need for high availability.
Speaking of availability, NUMA inherits the high availability woes of SMPs for exactly the same cache-coherence reasons: If a processor goes down for the count, the modified data in its cache(s) is no longer available, so other processors will either get the wrong data or hang. Furthermore, NUMA systems, like SMPs, contain a single copy of the operating system. Unlike clusters, you can manage a NUMA system of any size as a "single machine."
Anything that enhances system management is obviously useful. However, having a single operating system also means you have a single copy of operating system data spread across the machine. A processor (or node) going down will, like on an SMP, leave unique locks held forever and have other bad effects, eventually causing system failure. If a single processor bites the dust anywhere in what may be a 100-processor NUMA system, the whole system goes down.
This characteristic is even more incongruous than in the SMP case. Those NUMA nodes sure look like they're separate computers--surely most of them can keep going if some remote processor takes a dive? Again, the answer is no. The very things that make NUMA desirable--the SMP-like memory sharing among processors and the single operating system--make its parts so interdependent that a single dead node turns the rest of the machine into an expensive doorstop. For true high availability, what you need is a cluster.
CLUSTERS
A cluster is a connected collection of whole computers that are used as a single resource. "Whole computer" means what it sounds like: A complete computer system that has everything it needs to function, including processors, memory, I/O, a copy of the operating system, subsystems, applications, and so on. Regular, off-the-shelf computers do just fine; they can be SMPs or they can even be NUMA systems. (This fact often clouds the NUMA availability issue because most NUMA vendors also offer clusters, thereby bestowing high availability.)
"Single resource" means that a layer of software lets users, managers, or even applications think there's just one "thing" there: the cluster, and not its constituent computers. For example, a cluster batch system lets you send work to the cluster for processing--not to a particular computer. Database systems offer a more complex example. All major database vendors have versions that run in parallel across multiple machines of a cluster. As a result, the applications using that database don't care where their work gets done; just as in an SMP, where you don't care which processor is used, the multiple computers of a cluster are used as a unit. The database takes care of locking among machines and ensuring consistency.
Clusters are interconnected in many different ways; the two most common variations are shown in Figure 3. Some form of direct machine-to-machine communication is almost always involved. It can be as simple as Ethernet or as complex as a high-speed, hundreds-of-megabytes-per-second network such as those used by IBM's RS/6000 SP, Digital's Memory Channel-based systems, or Compaq Computer Corp.'s (once Tandem's) ServerNet. In addition, the computers of a cluster often, but not always, allow any member of the cluster to get to any disk through I/O switching--whether through multi-initiator SCSI or SSA, a fibre channel switch, or proprietary means. That doesn't mean the computers necessarily "share" the disks in any meaningful sense; that's up to the database or other subsystem, and most of them adhere to a shared-nothing philosophy in which only one computer "owns" a disk at any time. Oracle8 and IBM S/390 DB2 are exceptions; they actively share disks--in effect treating them as big, slow memory on which database cache coherence is maintained.
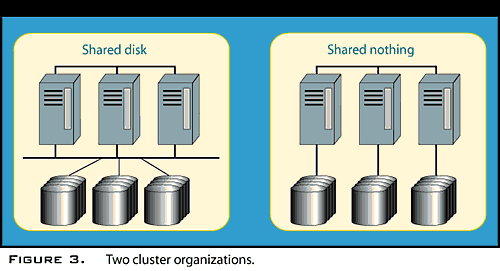
Clusters offer high availability because they don't run a single operating system, nor do they share memory in a cache-coherent manner. As a result, failures are contained within a single node. (They're called nodes in clusters, too.) In addition, monitoring software continually runs mutual checks, each node ensuring the others are still alive by looking for "I'm still awake" signals that are continually passed around. If these signals stop, failover is initiated; the presumably dead system is isolated from I/O access, its disks and other resources are attached to other nodes (including its IP addresses), and whatever jobs were running on the woebegone system are restarted on other nodes.
Performance and capacity can scale up with added cluster nodes, too. Clusters can run multiple separate applications but scaling up a single application requires that its parts communicate through messages. This is very different from programming an SMP, but if your applications run under a TP monitor or database, the monitor or database vendor has already done that work for you. What can't be hidden, however, is that communication across nodes takes much longer than in an NUMA system, not to mention an SMP. In many cases, TCP/IP is used as the communication protocol, a comparison of which to SMP cache-to-cache transfers is like that of continental drift to a jackrabbit. Proprietary protocols do much better, and an Intel-led consortium has proposed a low-overhead cluster communication API called Virtual Interface Architecture that bids fair to become the standard.
Once again, however, partitioning is usually the order of the day. Clusters have also done well on business intelligence applications in addition to other well-partitioned areas such as LAN consolidation and batch execution of multiple technical jobs. However, some clusters, such as IBM Parallel Sysplex, incorporate specialized hardware and software that overcomes internode communication penalties and allows even nonpartitioned OLTP to run efficiently.
In sheer maximum size, clusters have an advantage over NUMA systems. Not only do they offer high availability--and without that, really big systems with thousands of nodes aren't feasible--but also their lack of a single operating system means that nobody has to program the OS to run efficiently in parallel on many nodes. Consequently, cluster scaling is virtually unlimited, and massively parallel systems with hundreds or thousands of nodes have been used successfully.
The multisystem characteristic of clusters produces a downside, however: managing a cluster is like managing multiple systems. Tools can help, but the result has been, up to now, less satisfactory than that of the single system offered by SMP or NUMA. This problem is particularly vexing when considering failover for high availability; all the tuning and parameterization of a major subsystem had better be identical on all the nodes, or if (when) that subsystem has to fail over, it won't work right.
PARALLEL SUMMARY
Table 1 summarizes all the comparisons we've covered in our descriptions of these three parallel architectures. At this point, little in that table should come as a surprise--nor should the observation that, as I initially emphasized, none of these architectures is ideal. There is no, and probably never will be, any substitute for understanding your requirements, knowing what's available, and making the effort to consciously choose the compromise that best fits your needs.
| TABLE 1. Parallel architectures compared. | ||||
|---|---|---|---|---|
| Performance Scaling | ||||
| OLTP (not partitioned)* |
Decision Support (partitioned) |
High Availability | System Management | |
| SMP | Best of the lot, particularly for short transactions | Limited scaling | No. Single points of failure in hardware and OS | Single system |
| NUMA | Less likely to do well without lengthy transactions | Good scaling | No. Single points of failure in hardware and OS | Single system |
| Cluster | Difficult without hardware acceleration | Virtually unlimited scaling | Yes. Can be configured to have no single point of failure | Multisystem |
| * Popular OLTP benchmarks are highly partitionable and therefore offer good scaling where this table indicates otherwise. | ||||
Greg Pfister
is senior technical staffmember at IBM in Austin,
and is the author of In Search of Clusters (Prentice Hall, 1997). You can reach him at
[email protected].