Taking Advantage of Partitioning in Oracle8™
An Oracle Technical White Paper
June 1997
INTRODUCTION
While Oracle 8Æs partitioning feature can offer many systems significant performance improvements and increase ease of manageability, there are some critical decisions that need to be made during its implementation. These decisions, best made during the design phase of the database, allow users to gain the most from partitioningÆs benefits, while avoiding pitfalls that can cause partitioning to worsen performance. This paper provides a brief overview of the partitioning feature, but concentrates on how to use partitioning and indexing to improve manageability, performance, and availability.
PARTITIONING OVERVIEW
Oracle8 allows the user to functionally break down tables and indexes into smaller components, called partitions. Each of these components has similar attributes to those of the tables or indexes from which they are based, including their own TABLESPACE and STORAGE clauses, among others. A partition can be thought of as a new data dictionary layer between Tables/Indexes and Tablespaces.

Just about any Database Definition Language (DDL) or Database Maintenance Language (DML) statement that can be performed on a single table or index, can be executed on a partitioned table or on any single partition.
One of the biggest advantages of having partitioning as an extra dictionary layer is that changes required to implement partitioning in a database can usually be done at a schema level, without requiring a rewrite of the application code. Some batch routines, such as data loading or aggregation building, may need to be rewritten to take advantage of Oracle8Æs added parallelism.
Tables
Partitioning allows the user to partition tables into any number of separate partitions based on a partition key or key range, which can be comprised of one or several columns. All insert, update, or delete operations can be handled automatically through the use of this key.
Indexes
Indexes can also be partitioned. They can either be managed independently, in which case they are known as global indexes or automatically linked to a table's partitioning method, in which case they are known as local indexes. Local indexes, because they are equipartitioned with the table and each table-index pair is independent from the rest, are easier to manage and offer greater availability.
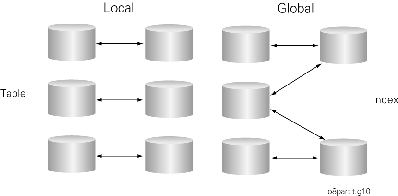
The ability to build global indexes is a key difference in Oracle8's Partitioning from Oracle7.3's Partitioned Views, which could only do one index per partition.
Global indexes have the flexibility in that the degree and key of partitioning is independent from the table's partitioning method. So a global index could be used only to have a single index for a partitioned table, to have a partitioned index for a non-partitioned table, to have a different degree of partitioning, or to partition by different columns (key) than the base table.
Local partitioned indexes are easier to manage and offer greater availability. Equi-partitioning allow's Oracle to automatically keep the index partitions in synch with the table partitions and makes each table-index pair independent. Any actions that make one partition's data invalid or unavailable won't affect the rest, increasing the overall availability of the data.
Global partitioned indexes are harder to manager and don't offer as great availability gains. Management of these must be done manually and any operations such as dropping, truncating, exchanging, or splitting any table partition will make all of the indexes unusable, as any index can now have invalid data. While some availability gains are still made over non-partitioned indexes, should one index partition become unavailable it would affect access to multiple table partitions.
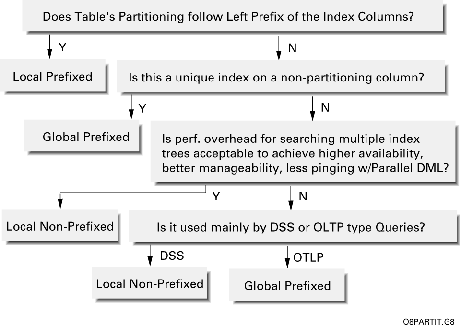
A partitioned index is either prefixed or non-prefixed depending on how it is partitioned relative to the index.
An index is prefixed if it is partitioned by a left prefix of the index key. It has the potential for better performance, as any particular row is guaranteed to only portion of the index.
An index is non-prefixed if it is not partitioned by a left prefix of the index key. It has the potential for worse performance, as any particular row is guaranteed to only be in one portion of the index. Details on this will be given later.
This allows a total of four options as can be seen in Figure 4: global prefixed, global non-prefixed, local prefixed, and local non-prefixed, of which three options are allowed in Oracle8. Global non-prefixed indexes are not allowed as there is neither performance nor manageability gains for having them.
Table with Columns (A, B) partitioned by A.
| Index partitioned by A | Index partitioned by B | |
| Index on A | Local, Prefix | Global, Non-Prefix |
| Index on B | Local, Non-Prefix | Global, Prefix |
ATTAINING IMPROVED MANAGEABILITY
The ability to manage partitions individually or as a whole offers a tremendous amount of flexibility over non-partition systems, which do not offer the detailed control, or over systems using Oracle7.3 Partitioned Views, which lacks the ability of global control. Each maintenance operation which beforehand could only be performed on a table/index, can now also be performed on an individual partition, without affecting the rest of the partitions.
The following are some of the gains made from individual control of partitions:
Higher Availability of Objects
Higher availability is gained by the independence of the partitions. This independence allows the remaining partitions to be available should one become corrupt, need be excluded by some batch process, or reside on an unavailable tablespace.
Batch Deletes
Batch deletions can be quickly completed by truncating a single partition instead of deleting a range of data. For example, in an orders table which keeps the last 12 months of data, and is partitioned by month, the last month can be simply truncated when no longer needed.

Independent Tablespace Assignment
Assignment to different tablespaces allows data locality to be controlled by ensuring that an update or insert will go to a specific tablespace. This additional control can be useful for tuning purposes (by improving manual striping ability among others) and for reducing pinging in a Parallel Server environment. It allows the use of read-only tablespaces for partitions that are not being inserted into, which can reduce and simplify the backup and restore processes.
Control over Partitioning Schema
Control over how partitioning is implemented is also improved with partitioning. Granularity can be easily added or removed to the partitioning scheme by splitting partitions. Thus, if a tableÆs data is skewed to fill some partitions more than others, the ones that contain more data can be split to achieve a more even distribution. Partitioning also allows one to swap partitions with a table. By being able to easily add, remove, or swap a large amount of data quickly, swapping can be used to keep a large amount of data that is being loaded inaccessible until loading is completed, or can be used as a way to stage data between different phases of use (for example: current days transactions, on-line archives).
For example, data warehouses periodically bring in a new data set that will be appended to the current data set of a table. Assume that the table is partitioned so that each new data set will go into a separate partition and local indexes are used. This data set can then be loaded into a separate table, its index created, and both objects analyzed for statistics without affecting the original partitioned table. Once the load and index build is complete, the table can be swapped for one of the partitions. This allows one to avoid any problems that may be associated with users selecting data that is being loaded, such as having a partial data set available, a slow index build, or pinging in a parallel server environment. The whole index doesnÆt need to be rebuilt nor does the whole table need to be reanalyzed. Similarly, once data from a partition needs to be eliminated, it can be done so by truncating the partition instead of deleting the rows, which is much slower.
ATTAINING IMPROVED PERFORMANCE
Achieving Performance Gains With Partitioned Tables
Partitioning is useful in improving performance because it breaks down data according to a partition key. This separation allows for independent treatment of partitions as mentioned in manageability, reduces the number of partitions being hit by eliminating partitions, or brings back more of the needed rows in a single I/O by improving data clustering.
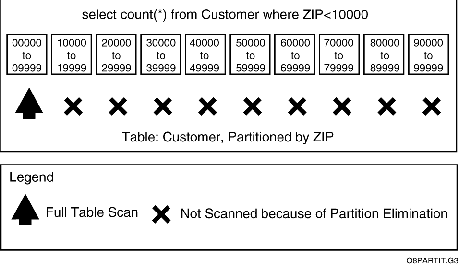
Partition Elimination
Partition elimination allows one to avoid the cost of going after the whole table for a small subset of rows. Queries that use specific portions of the table by using the partitioning columns in the "where" clause, benefit from not having to access the partitions that can be eliminated.
For example, this and the next example use a customer table partitioned with an index on ZIP, both of which are partitioned ten ways by ZIP with an interval of 10000.
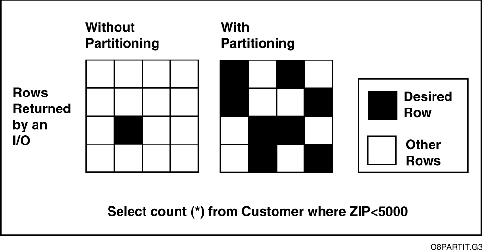
Improved Data Clustering
Partitioning causes data clustering by grouping data that is similar (i.e., falls in the same partition) together. A query and/or DML that is selective according to the partitioned column and hits multiple rows would gain from the greater likelihood of getting more æcorrectÆ rows from a single database access.
How to Partition a Table
Maximum benefit is gained from partitioning when the index returns multiple rows and/or a full-table scan can be used instead and access is gained by the partition key. Little if any benefit occurs when an index is used to find a "rowid" and return one row. So the important aspect in analyzing which way to partition is to see which way database operations potentially gain the most by these improvements.
A good hint for ways to partition a table is to look at its indexes because:
- Good indexes are ordered by selectivity
- Queries will tend to be by index order
- Partitioning incorrectly for the main index used can be very costly
Updates of partition key columns are only allowed when these do not cause row migration between partitions. Otherwise independence of partitions would be lost, and the ability to do Parallel DML would be limited. For non-Parallel DML operations one can implement an trigger than would do a delete and insert instead of an update.
Achieving Performance Gains With Partitioned Indexes
While index partitioning is similar to table partitioning in that it can gain from partition elimination, it can also gain from being able to scan multiple index trees in parallel. One disadvantage is that sometimes multiple indexes may have to be searched.
Partition Elimination
Indexes take advantage of partition elimination in a similar way to tables, and as index partitioning is independent, this may or may not occur at the same time as partition elimination for tables.
Yet, as indexes are built on B-trees, the gains from partition elimination from each access is little, and thus, it is really only taken advantage of when the index is used to return multiple rows.
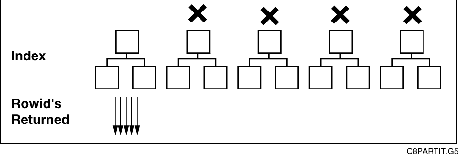
Scanning Multiple Index Trees in Parallel
When multiple indexes need to be scanned, such as when partition elimination is not possible or elimination leaves more than one index, Oracle8 is able to scan all the partitioned indexes in parallel, having one process per partition. This is especially useful for doing index range scans.
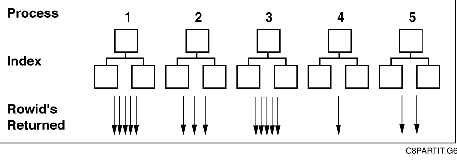
Having to Search Multiple Indexes
Partitioning an index can be disadvantageous if later this index is to be used in a form that is contrary to the partitioning method, forcing Oracle8 to search various trees instead of just oneùespecially if the scan must be done serially. Fortunately this can only happen with non-prefixed indexes. The added cost for this operation, where n is the degree of partitioning and x is the number of rows, approaches n as x gets larger. This means that a table with x rows has an index of height log2(x). With an index partitioned n ways there would be n indexes each with a height of log2(x/n) versus one index of height log2x. To scan all indexes to find a certain row, the change in performance would be nlog2(x/n)/ log2x = (nlog2x - nlog2n)/ log2x = n - (n log2n / log2x). As x >> n this value will eventually approach n.
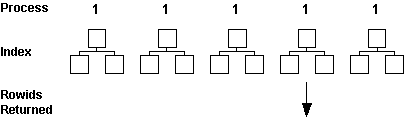
How to Partition an Index
The two items to keep in mind when partitioning indexes are that prefixed indexes can always take advantage of partition elimination and local indexes are much easier to manage.
If partitioning the index proves useful, the following table can be helpful in determining which way the index should be partitioned (assuming that the table is also partitioned):

Achieving Greater Parallelism
Partitioning permits more aspects of Oracle8 to be parallelized by concurrently permitting a process to work on each partition. By permitting one process per partition, instead of one process per table/index, the following can now be done in parallel to a partitioned table:
- All DML activity (known as Parallel DML)
- Direct Loads w/Indexes Pre-created
- Estimating/Calculating Statistics
- Export/Import of Table Data
- Scan of Index B-Trees
CONCLUSION
Partitioning proves itself a powerful tool for improving database performance, availability, and manageability making large systems practical. Achieving these benefits requires careful analysis of data structures, batch processes, and parallelism needs, before actual implementation of partitioning can be done.
![]()
Oracle Corporation
World Headquarters
500 Oracle Parkway
Redwood Shores, CA 94065
U.S.A.
Worldwide Inquiries:
+1.415.506.7000
Fax +1.415.506.7200
http://www.oracle.com/
Copyright © Oracle Corporation 1997
All Rights Reserved
This document is provided for informational purposes only, and the information herein is subject to change without notice. Please report any errors herein to Oracle Corporation. Oracle Corporation does not provide any warranties covering and specifically disclaims any liability in connection with this document.
Oracle is a registered trademark and Enabling the Information Age, Oracle8 is a trademark of Oracle Corporation.
All other company and product names mentioned are used for identification purposes only and may be trademarks of their respective