By Erik Peterson
A highly successful team can successfully distribute work while minimizing contention over resources so that the team members can accomplish their tasks without tripping over each other's feet. Similarly, a set of Oracle instances working together as a parallel server must be able to divide work and coordinate the collective tasks. And just as not all tasks lend themselves to a team approach, not all systems lead themselves to being made parallel. However, by properly partitioning resources and tasks--and by coordinating these partitions and the actual application--many users of Oracle Parallel Server can significantly improve performance and achieve scalability beyond that available from a single-node symmetric multiprocessing system, NUMA system, or even a large mainframe.
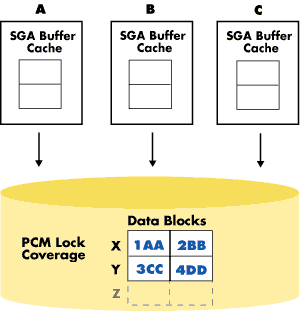
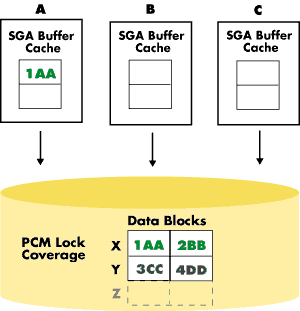
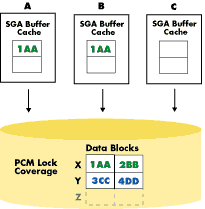
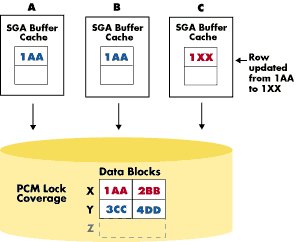
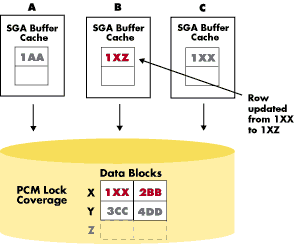
Imagine, for example, that a user in one instance wants to read data that another user in another instance has updated and committed, but whose changes have not yet been written to disk and are still being held in the original instance's database buffer cache. Oracle Parallel Server handles this situation by adding another level of locks, called Parallel Cache Management (PCM) locks, which ensure cache coherency.
PCM locks work in conjunction with the Distributed Lock Manager (DLM) to handle the locking of resources such as data blocks, rollback segments, and data dictionary entries. Oracle assigns PCM locks on a per-datafile basis in the case of hashed locks, or on a per-block basis in the SGA in the case of Data Block Address (DBA) locks (available in Oracle7 Release 7.3 or higher). The granularity of coverage of the locks is user definable, and thus a lock can cover one block or several.
PCM locks can exist in an instance in any of three modes:
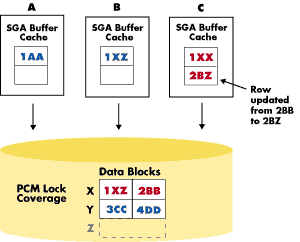
Because pinging is typically what limits application scalability most, the goal is to eliminate or minimize false pinging and reduce real pinging to a very low level. This involves two factors: One is the method of assigning PCM locks and their granularity, which is discussed thoroughly in the Oracle7 or Oracle8 Parallel Server Reference Guide. but a second, even more important, factor is application partitioning.
Consider an application that stores names of medications approved by the U.S. Food and Drug Administration. The system gets relatively few writes (updates or inserts), while reads (selects) are very common, which means little or no partitioning is necessary. A similar system that stores driver's license information may not seem like it would need partitioning. While updates and inserts are common, they rarely occur to the same row from two sites simultaneously, since a person cannot be in more than one Department of Motor Vehicles office at once. Similarly these updates cover only a very small percentage of overall rows. Even so, pinging can still cause trouble in this situation because pinging occurs across blocks or groups of blocks instead of rows. Therefore, proper design and partitioning are critical and affect overall system performance.
You should also place data that is updated, inserted, deleted only in a large batch (or batchlike process) in separate tablespaces. You can then track when this data is created or modified and treat it as read-only at all other times. If you are erasing old data and entering new data, truncate the rows instead of deleting them to prevent a search to the old high-water mark for full table scans.
Finally, although the data in this case is rarely modified, and then only by controlled batch procedures, the timing of updates, deletes, and inserts is often unpredictable and may occur simultaneously with reads. Yet this contention will be very different from the non-batch modifiable data. Therefore, this batch data should also be separated into its own tablespaces and require PCM lock assignment. Here it is assumed that updates, deletes, and inserts are infrequent enough that they will cause little data contention; otherwise treat it for partitioning like other modifiable data.
If updates, deletes, or insertions become more frequent, you may have to do some partitioning may to avoid contention occurring between instances. Localize all data contention to the same instance as much as possible. An application that is overly subject to data contention and cannot be partitioned is not an appropriate candidate for an Oracle Parallel Server environment.

In this example, separate instances exist for each database but only one instance is used at a time. While this simple case may have little to gain from an Oracle Parallel Server environment, it illustrates a valid method of partitioning. A practical application of this example would be a company that runs its accounting and human-resources systems on different databases. Both systems are mission critical and must be highly available. Because they are also physically separate, they are good candidates for partitioning by database.
| Advantages | Disadvantages |
| Gain automatic failover capability of Oracle Parallel Server. | Workload may not be evenly divided between nodes. |
| No pinging occurs because intercommunication is absent. | Each application is limited to the capacity of the node on which it resides. |
| There is no need to partition database or its applications. | Instances must be shifted in one piece. If three nodes run three different instances and one node fails, it would result in one node with two instances and the other with only one. |
| Each node must have extra capacity in case of node failover; the extra capacity can otherwise only be used by 'local' active instances. |
Partitioning by module (as in Figure 8) is similar to the partitioning by database, except that the partitioning occurs within database modules or applications. In this case, a is module a disjoint set of tables that are commonly used together, plus any processes that access this set of tables. For example: a company�s human resources department has two modules in its database--benefits and recruiting--which are completely independent and can be easily separated from each other.
| Advantages | Disadvantages |
| Gain automatic failover capability of Oracle Parallel Server. | Workload may not be evenly divided between nodes. |
| Gain scalability of multiple nodes while still having all modules in the same database. | Each module is limited to the capacity of the node on which it resides. |
| No pinging occurs if modularization can be done in disjoint sets, as no intercommunication occurs. | Each node must have extra capacity in case of node failover; the extra capacity can otherwise only be used by 'local' active instances. |
| Other partitioning schemes may be combined with this should a module need more capacity than can be provided by one node. | Intercommunication between modules can produce pinging if modules are not completely separate or if one module spans multiple instances. |
| Database must be partitioned into modules. | |
| Modules must be shifted in one whole piece. |

The idea underlying partitioning by users is that you can create groups of users that access data in a similar fashion to separate sets of users. For example, a real estate firm might wish to separate its users into northern and southern groups so that for transactions where the contention might be high--such as reserving properties for showings--it would occur on the same node and would avoid pinging. You can also partition applications in such a way that different user accounts get used by the same person to do different tasks.
For example, a system could have a northern user account on a northern instance and a southern user account on a southern instance for the same person. That person could then use the appropriate user account. At an application level, you will need to route the user accounts to the appropriate instance.
| Advantages | Disadvantages |
| Gain automatic failover capability of Oracle Parallel Server. | Workload may not be evenly divided between nodes. |
| Easy if geographic, work type, or other factors offer clear ways to differentiate users. | Each user is limited to the capacity of the node on which it resides. |
| No pinging occurs if different sets of users access disjoint sets of data. | Each node must have extra capacity in case of node failover; the extra capacity can otherwise only be used by 'local' active instances. |
| Users do not always fit neatly into one group. | |
| Access may not be completely disjoint and pinging can occur from intercommunication between users. | |
| User groups must be shifted in one whole piece. | |
| A node without failover capability could shut down a whole group of users. |
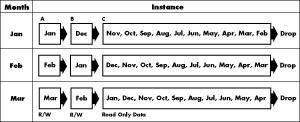
Instead of putting access to different tables on different nodes, all nodes can access all tables while only certain rows are accessed (in contention-causing cases) for each instance. This process is greatly facilitated by the Partitioned Views feature in Oracle7.3 and by Partitioned Tables and Indexes in Oracle8. It is often desirable to have the same table worked on by different nodes. In these cases, instead of putting access to different tables on different nodes, all nodes can access all tables, while only certain rows are accessed (in contention-causing cases) by each instance.
Partitioning table rows is especially useful when data has a time component that determines what operations should occur. For example, in a billing process, while the current month�s entries are created, the previous month�s entries are billed, and all entries are retained for one year before can be deleted. You could use one partition (instance A) for current inserts; use instance B for the billing batch process (with a guarantee that no one else will change it), and reserve instance C for occasional consultations and changes and the final deletion. At the end of each month, you can delete the partition for the oldest month and reuse the space for a new partition. Access is cleanly partitioned and you can access data either partially or as a whole.
While partitioning by time is great for limiting the scope of data currently being modified, the ability to make DML activity parallel can be limited because only one partition exists for any one period. You can also apply this method across other dimensions, such as geography, area code, social security number, or any other column that you can partition by range. With Oracle8 you can even partition on multiple columns (such as date and geography) to combine the benefits of time partitioning and the DLM parallelism of multiple partitions during a time period.
| Advantages | Disadvantages |
| Gain automatic failover capability of Oracle Parallel Server. | Workload may not be evenly divided between nodes. |
| No partitioning of users is necessary. | Access performance of covered rows is limited to the capacity of the node to which they currently belong. |
| Since the whole table will be cleared, you can truncate, rather than delete, rows, which is more efficient and leaves the space better organized. | Each node must have extra capacity in case of node failover; the extra capacity can otherwise only be used by 'local' active instances. |
| Data within a partition can be further partitioned into smaller time slices or divided with other methods to allow multiple instances to insert or run modifying processes on the data. | Data must be partitionable by time of entry, geography, or another similar means. |
| A subset of the data is available in a read-only form (as with the previous month's data in the example). | Over time data skewing can occur, which unbalances the workload. |
| Provides effective way to eliminate true pinging by understanding user requests. | Access by other instances to data being inserted or modified will cause pinging. |
| Permits an easy, assembly-line way to work on rows. |
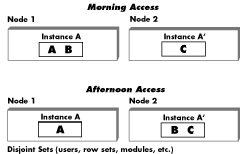
Time-based partitioning is generally used with other partitioning methods to provide a flexible way to balance work among nodes or to shift sets by time. In the diagram above, common processing (or high contention-causing processing) between sets A and B has to occur in the mornings while set C can work completely independently. In the afternoon, set A can work independently whereas B and C--which are in contention--need to be on the same node to avoid a high level of pinging.
| Advantages | Disadvantages |
| Allows dynamic load balancing. | Load-balancing ability limited by granularity of other partitioning. |
| Can combine it with other partitioning schemes. | Use of a set must be disjoint in time between two nodes otherwise pinging can occur between them. |
Hashed Locks keep all acquired locks in memory and their granularity of coverage is user-definable. These are preferable in areas where fewer locks are required and where you have very little inter-instance contention. Use them with read-only tablespaces or tablespaces that are properly partitioned to avoid pinging.
Partition tables and other database objects into separate tablespaces according to their lock usage. If they will use different locking mechanisms, put them in different tablespaces. In the case of hashed locks--where lock-coverage granularity is definable at the datafile level--partitioning is necessary because some data (such as that in read-only datafiles) will have no pings and need only one PCM lock, whereas other data (such as occasional updates) will have some pinging need more PCM locks to avoid false pinging. The latter case can lead to several levels of granularity of lock assignment, as needed.
For example, one customer site had 528 sequence generators (and therefore 528 rows in SYS.SEQ$ table), but these rows filled only 11 blocks. Even if the locking granularity were as fine as one lock per block and each instance accessed different sequences, you could still get a very high level of pinging.
If the database has not yet been created--or you�re willing to recreate it to avoid this--modify the $ORACLE_HOME/dbs/sql.bsq file that creates this table and alter set SEQ$ to use the following additional parameters:
pctfree 99 pctused 1 storage (initial 100k next 100k pctincrease 0).
This will cause only one row to exist in each block, which sacrifices some space, but provides some hope of controlling pinging for the object. Don't worry about pctfree being set to 99; Oracle will always insert at least one row into a block. Note that modifying this file or any other of these database-creation files, is not officially supported. Use it at your own risk and try it first on a test database.
Sequences can cause pinging problems even if they are distributed over several locks. Sequences--and similar mechanisms that simulate sequences (look up a value in a table and increment, for example)--are serial operations which can slow database performance. You can reduce pinging to a very low level by increasing the cache used for the sequence, However, you may want to replace a single sequence generator with an individual sequence generator for each instance if possible, because these could not repeat values between them. Users would have know what instance they are accessing in order to point to the correct sequence; but many of the above partitioning methods provide adequate information. The two methods shown here provide the additional advantage that a user could later tell which sequence (and thus which instance) generated which value--the second method may possibly do this more efficiently.
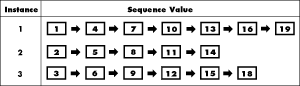
Although each sequence works independently, it is guaranteed to generate a new, unrepeated, value. This method has two drawbacks: one, a larger value does not guarantee a later creation date, and two, adding another instance requires restructuring sequence generations. The former is shown in this example, where sequence value 19 has already been created but sequence value 17 may be created in the future. To satisfy problems caused by the later case, you would have to find the next highest value (say, V) of all of the sequences and then rebuilding all the instances using V+X as a start point and incrementing by the new value of N.
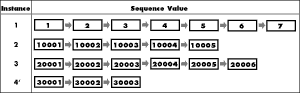
Instance 4' shows how you can add another instance at any time following the same rules without affect the existing sequences. The principal disadvantage of this method is that you must leave large gaps between sequence numbers and correctly estimate the size of these gaps beforehand to avoid overlapping. In addition, you can�t distinguish new sequences from those whose value was created first.
Effective partitions--combined with load-balancing methods, such as TP monitors--allow all clients to access data only where it is the most reasonable, and keeps data separated into pieces that are easier to backup and restore. Still, partitioning is not a trivial matter and you can�t always apply it to an application just before it goes into production. Partitioning can change the way that data is used and laid out, and hence also change the basic structure of the application. It is best applied at the early stages of application design, when the application is the most flexible to partitioning.
Erik Peterson ([email protected]) leads the worldwide Oracle8 QuickStart virtual team and is a member of Oracle Consulting's Enterprise Scalable Solutions Center of Excellence. He has been actively involved with Oracle Parallel Server for the last three years, helping many customers build very large, scalable, and highly available implementations using Parallel Server as well as actively working with the product development team to improve the product.