In this final part of his tuning series, Roger overviews transaction -managment and locking strategies and discusses some design issues for distributed computing in large scale environments.
In the first two parts of this series I covered a lot of ground, including discussions of bind variables, SQL optimization, stored procedures, triggers, and index usage. In this, the third and final part, I conclude my discussion of the nebulous topic of application tuning with an overview of transaction management and locking strategies. I also briefly discuss some design issues associated with distributed computing in large-scale environments.
When developing an understanding of transaction management, it is helpful to discuss the features of the database server that facilitate transaction processing. Because your concern is application performance, you want to take best advantage of your database's services. To this end, it might be helpful to develop an understanding of the Oracle7 RDBMS engine by comparing its transaction-management features to those of two of its competitors: Sybase and Microsoft SQL Server. Although it might seem extraneous to discuss other database products when our focus is clearly Oracle, my personal understanding of Oracle developed considerably when I found myself supporting other products and had to quickly learn a different approach. My hope is that a discussion of different approaches will round out your collective knowledge and help you better understand your own architectures. Of course, space here permits only a limited, conceptual view of database transaction-management internals.
Because Microsoft originally licensed its SQL Server technology from Sybase, the two products are architecturally linked. For the sake of simplicity, I discuss them as though they are one product. It is important to note, however, that some of the limitations of that architecture have been addressed by Sybase with its latest release, Sybase System 11. Also, Microsoft has made some changes to its architecture with SQL Server 6.5 that begin to address other limitations. With those caveats in place, let's forge ahead and describe the transaction-management process.
The nature of a database transaction revolves around the notion of a
unit of work. SQL statements that update and insert rows in a database are
not always issued alone. In a business application, multiple tables are
typically updated together. For example, orders and order line items are
often created in tandem. If there is a problem with one, we normally presume
that there is a problem with the other. To maintain integrity between tables,
database vendors provide both a commit and a rollback mechanism. When an
end point in a group of related database changes is reached, the application
will either commit or roll back the work. The idea, of course, is that changes
are grouped such that the related changes are applied either all correctly
or not at all. This grouping constitutes a unit of work. Application developers
must design their applications with the boundaries of such a unit of work
in mind. From the viewpoint of the database engine, this unit of work, or
transaction, consists of all database changes from one commit to the next.
Some database products allow the application to explicitly define the beginning
of a transaction with a BEGIN TRANSACTION statement. Some database
products such as Oracle, however, implicitly begin an application's first
transaction after connect, with the first SQL statement that is issued,
and end a transaction with either a COMMIT or ROLLBACK
statement, at which time a new transaction begins.
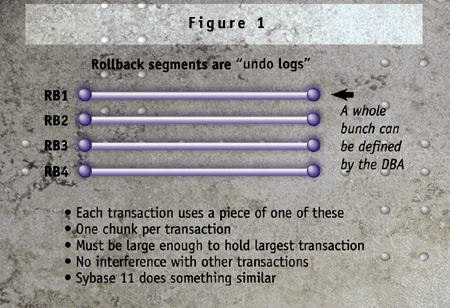
When a transaction does end, the database either is at a new, correct state or must be restored to the exact state seen by the application at the beginning of the transaction. Obviously, to restore the database to its pretransaction state requires a bit of work. Oracle uses a structure known as a rollback segment to accomplish this. A rollback segment is a physical data structure within a tablespace. In use, this information is normally maintained in the System Global Area - the memory structure in which Oracle's data caching normally occurs. A DBA defines rollback segments to accommodate the largest transactions that will be generated by the application. If the rollback segments are not large enough at runtime, or if not enough of them have been allocated, the application will encounter errors. Sometimes Oracle application developers will encounter a seemingly cryptic message - "snapshot too old" - when an application is deployed to a production environment. This error means that rollback segment information was no longer available to a long-running query, having been overwritten by a different transaction. Rollback segments are fairly resilient structures in that they can grow and shrink to accommodate a dynamic environment. Nevertheless, they are by no means foolproof. Errors may not show up during the development phase, because the production database configuration may dramatically differ from the development environment.
At the start of a transaction, Oracle assigns it a single rollback segment.
When a rollback is issued to Oracle, all of the change information contained
in the rollback segment associated with this transaction is applied back
to the database to "undo" the changes made by the transaction.
All rollback data generated by a transaction must fit into a single rollback
segment, although a rollback segment can be shared by multiple transactions.
(See Figure 1) Because a rollback segment must be large enough to contain
changes made by the largest transaction, it is imperative that application
developers and DBAs operate together to develop a workable design, providing
enough rollback segments of the correct size, while at the same time carefully
managing the application design to be not too greedy with database resources.
 Once a transaction completes, as defined by the receipt of a COMMIT
statement, Oracle copies the transaction information to the redo log. The
redo log is written to a disk file physically external to the database itself.
This log is used during database recovery, after a system failure, to permit
transactions to be replayed or rolled forward. This log causes transactions
to be reapplied to the database and its state restored to a point before
a failure occurred. The fact that the redo log is external to the database
and that it is maintained as each transaction completes is quite important
to the performance and integrity advantage that Oracle maintains over its
competitors.
Once a transaction completes, as defined by the receipt of a COMMIT
statement, Oracle copies the transaction information to the redo log. The
redo log is written to a disk file physically external to the database itself.
This log is used during database recovery, after a system failure, to permit
transactions to be replayed or rolled forward. This log causes transactions
to be reapplied to the database and its state restored to a point before
a failure occurred. The fact that the redo log is external to the database
and that it is maintained as each transaction completes is quite important
to the performance and integrity advantage that Oracle maintains over its
competitors.
The Sybase/SQL Server architecture is quite different when it comes to transaction management. All undo and redo information is contained in a singe database structure - the transaction log - within the database. See Figure 2 for a graphical illustration of this architecture. The transaction log is like a giant rollback segment and redo log combined. For many applications this structure works quite well. Unfortunately, recovery can be a problem. Each time a transaction completes (that is, a COMMIT or ROLLBACK is issued), a high-watermark is moved in the log to the beginning of the next open transaction. Remember that a transaction is open until either a ROLLBACK or COMMIT is issued to the database. If an application begins a transaction in the morning and, for some reason, it is neither committed nor rolled back until that evening, every transaction generated during the day is treated as though it is still open.
 Periodically, the transaction log is dumped to an external file, which
is then available for database recovery. At that time, it behaves as a redo
log. When the transaction log is dumped, all completed transactions are
cleared. If a transaction is open for many hours, never to complete, it
is included in the dump file but is never cleared. More important, transactions
that complete after the beginning of the still-open transaction are not
cleared either, although they are all dumped to the external disk file.
If the database server crashes during the day, an automatic instance recover
occurs, similar to what happens in Oracle. Each transaction in the log since
the beginning of the oldest open transaction is rolled forward.
Periodically, the transaction log is dumped to an external file, which
is then available for database recovery. At that time, it behaves as a redo
log. When the transaction log is dumped, all completed transactions are
cleared. If a transaction is open for many hours, never to complete, it
is included in the dump file but is never cleared. More important, transactions
that complete after the beginning of the still-open transaction are not
cleared either, although they are all dumped to the external disk file.
If the database server crashes during the day, an automatic instance recover
occurs, similar to what happens in Oracle. Each transaction in the log since
the beginning of the oldest open transaction is rolled forward.
With a single, internal recovery log containing both open and closed transactions, instance recovery could take a considerable amount of time. Each transaction must be rolled forward from the beginning of the oldest open transaction. In the Oracle architecture (see Figure 1), each transaction has its own space on a rollback segment. Moreover, each transaction is written to the separate redo log, outside of the database, after it completes. If one transaction is open all day and the server fails, other transactions are not affected. Instance recovery is fast and simple. In Sybase's System 11 architecture, private transaction logs are available to mitigate this problem.
None of this is meant to suggest that one database architecture is inherently superior to another, nor is it my intent to instigate a database-religion flame war. It simply means that they are different in important ways and that application developers need to take these differences into account, hopefully during the early stages of development.
One obvious disadvantage of the Oracle architecture is that, because each transaction occupies no more than one rollback segment, long-running transactions can be a problem. You must have enough of them, and each must be large enough to support the application's largest transaction. Of course, Oracle provides facilities for limiting resource usage and killing sessions that are idle for too long, but rollback segments are resources that must be managed carefully. Designers are encouraged not to mix transaction-processing applications with decision-support or batch applications on a single database, because decision-support and batch systems typically need fewer, large rollback segments. There are other, internal resource issues that discourage the mixing of transaction processing and decision support, but rollback segment contention is no minor matter. Clearly, the Sybase/SQL Server architecture does not suffer from this limitation, because all transactions share one huge transaction log. Sybase and SQL Server have other issues, however, related to their page-level locking approach, and they don't really fare any better in a mixed decision-support and transaction environment.
One workaround for the support of occasional long-running Oracle transactions is to allocate a very large rollback segment and assign a large transaction to it discretely. To do this, at the beginning of the transaction issue a SQL statement similar to:
SET TRANSACTION USE ROLLBACK SEGMENT hugerollbacksegment;
When transactions begin, Oracle automatically assigns a rollback segment
in a round-robin fashion. Using the SET TRANSACTION
statement allows the application to be assured that a particular, correctly
sized rollback segment is available. Unfortunately, nothing prevents other
transactions from sharing the segment, so it is important to size the rollback
segment properly. You can guarantee that a particular transaction uses a
particular rollback segment, but you can't prevent Oracle from assigning
another transaction to it as well.
As mentioned above, a transaction is complete when a COMMIT or a ROLLBACK is issued. One useful and often overlooked feature of Oracle7 is the availability of a partial rollback, in the form of a savepoint. A savepoint is a sort of interim transaction marker that is declared with the following command:
SAVEPOINT savepointname;
This command can be issued by the client application at any point in
a transaction. It is useful for implementing a partial rollback so that
you can take corrective action before proceeding further with the transaction.
In the client/server GUI world, partial rollbacks are especially useful
when a transaction spans multiple windows. Because windows are typically
under the control of the application user, the application designer cannot
be sure whether a user will click an OK button or a Cancel button. For example,
a customer-related transaction might begin in one window, which has a control
button permitting the user to add optional, multiple comments to a child
CustomerComment table. (See Figure 3) The first window issues some SQL that
created a row in the Customer table, and the second window inserts one or
more rows in the CustomerComment table.
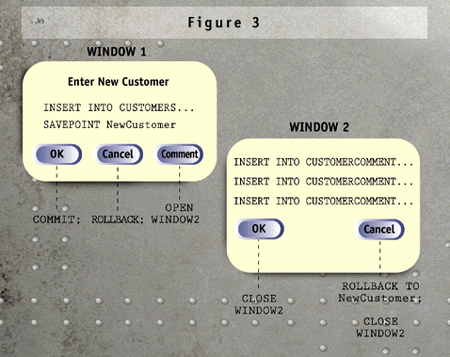 You might need referential integrity between the two tables, so a transaction
must include both the Customer insert and the optional CustomerComment insert(s).
The problem is that the comments entered in the second window involve multiple
SQL statements that might be canceled by the user. Once the inserts are
issued, they are part of the transaction. By issuing a
You might need referential integrity between the two tables, so a transaction
must include both the Customer insert and the optional CustomerComment insert(s).
The problem is that the comments entered in the second window involve multiple
SQL statements that might be canceled by the user. Once the inserts are
issued, they are part of the transaction. By issuing a SAVEPOINT
command as you exit the first window, the Cancel button on the second window
can then issue the a ROLLBACK TO SavePointName statement, should
the user change his or her mind. The syntax and workflow sequence might
look something like:
(Window 1) INSERT INTO CUSTOMERS (account, name, address, city, etc) VALUES (:Acct, :Name, :Addr, :City); SAVEPOINT newcustomer; (User clicks COMMENTS button; Window 2 opens.) INSERT INTO CUSTOMERCOMMENT (account, comment_text) VALUES (:Acct, :Comment); . . .
(Other comments are entered and inserted into table.)
(User decides not to enter comments after all and clicks Cancel button on
Window 2.)
ROLLBACK TO newcustomer;
(Window 2 closes; Window 1 regains focus.)
At this point, Oracle rolls back all of the INSERTs issued
after the declaration of the SAVEPOINT. The transaction is
still alive, and the customer can either COMMIT, presumably
by clicking an OK button, or proceed to Window 2 and enter comments after
all. Regardless of user confusion or capriciousness, the transaction is
safe and hidden from view. Savepoints are managed chronologically from the
viewpoint of the server. In our example, if the user clicks OK on Window
2, the window is closed, returning focus to Window 1. If the user then clicks
OK on Window 1, the whole transaction is committed, including any SQL issued
during the life of Window 2, including all of the rows of CustomerComment.
You can issue multiple savepoints for any transaction, although each of them must have a unique name within the boundary of the current transaction. Notice that they do not facilitate a partial commit, but a partial rollback. Think of them as bookmarks for your transaction. With the advent of event-driven applications, savepoints can be a life saver for application developers.
Locking, like transaction management, is one of those issues that can be deceptive. The idea is straightforward enough: When a resource is locked, nobody else can change it. With locks, you can keep concurrent users from stepping on each other's data. Simple enough, but when you scale an application to enterprise proportions, resource contention caused by locking can be a major performance bottleneck. It may help to briefly discuss the types of locking available to Oracle developers and compare Oracle locking methods to the methods of its competitors.
Oracle supports two levels of lock: table and row. By comparison, Sybase/SQL Server also provides table locks; but instead of row locks, it only locks at the page level. A Sybase page is a 2,000-
character chunk of data, similar to an Oracle block. A page can contain more than one row, depending on the size of a row. Moreover, when Sybase applications attempt to lock one or more pages of data, with the intent of updating a row, all other application sessions must wait for that lock to be released before they can update different rows contained within the same page. Oracle does not implicitly wait for a lock to be released. When a locked row is encountered by an Oracle session, an error is returned immediately. The application can retry or give up - it's up to the developer to decide.
Oracle, because of its rollback segment architecture, allows a read-only SQL statement to be processed even while a row or table is locked. When a row is selected that has been updated and is still locked by another transaction, Oracle gets the pre-update version of the changed part of that row from the rollback segment and returns it to the application. This feature, known as read consistency, is an important distinguishing characteristic of Oracle. Oracle guarantees that each statement will have a consistent view of the database from the point in time at the beginning of the transaction containing that statement, unaffected by the open, uncommitted transactions of other users. This means that, for Oracle, writers do not block readers.
Sybase/SQL Server, by contrast, enforces read consistency by simply locking pages and preventing the rows from being read by other users. They must wait. In a large-scale environment, this is a major bottleneck. Long-running reports will cause transaction-processing users to wait for completion. As multiple users compete for common tables, they may block one another. Such blocking can involve several thousands of pages and telephone calls from frustrated users to harried database administrators. Often, the DBA must intervene and kill the offending process. With the Oracle approach, the worst thing that will happen in such a situation is that the long-running report may encounter "snapshot too old" errors. In any case, other users are not affected in the Oracle environment. Again, this discussion is not intended to be a criticism of Sybase/SQL Server. By understanding an architecture and its limitations, application designers can avoid bottlenecks and optimize performance.
In an environment with many concurrent users, locking by any method can present some problems. Obviously, if more than one user needs to lock the same row at the same time, somebody is going to be disappointed. In addition, if a user initiates a transaction and locks a row, and then walks away from his or her workstation to attend a meeting, that open transaction could prevent other users from doing their work.
The technique of establishing row-level locks during screen interaction is known as pessimistic locking. The idea is that rows that are to be updated are selected with the FOR UPDATE option so that a row lock is established. The user makes changes on the screen, presumably in a scenario in which no other user will want to update those same rows during that time. When the user is finished, he or she presses the OK button and the application issues its COMMIT. The locks are released and everybody is happy. Unfortunately, it isn't always so simple.
Consider a simple airline reservation system. (See Figure 4.) A customer phones a reservation agent and books a flight on a particular airplane. A seat is represented by a single row in a table in the database, as is the airplane and the customer. Because only one person can occupy a seat at one time, locking the Aircraft_Seat row is a good idea, to prevent double-booking that seat. It is not likely that one customer will be talking to more than one reservation agent at one time, so locking the Customers table row is probably not necessary. On the other hand, it is quite reasonable that more than one customer will be booking some other seat at the same time on this same aircraft. Although there may be some need to update a column for this airplane's row, holding a row-level lock on the Aircraft table will cause contention and have a negative impact on the airline's ability to do business on a large scale. Therefore, row-level locking on the Aircraft table is not a good idea.
 By contrast, optimistic locking defers the row lock until the user has
completed data changes in the application and is ready to commit the changes
to the database. The word "optimistic" refers to the expectation
that no other user will update the same rows while the first user is doing
his or her work. As such, the application does not issue a lock until it
is ready to apply changes to the database. Just before the rows are updated,
the rows are selected again, and the columns are compared to a copy that
was made after the original
By contrast, optimistic locking defers the row lock until the user has
completed data changes in the application and is ready to commit the changes
to the database. The word "optimistic" refers to the expectation
that no other user will update the same rows while the first user is doing
his or her work. As such, the application does not issue a lock until it
is ready to apply changes to the database. Just before the rows are updated,
the rows are selected again, and the columns are compared to a copy that
was made after the original SELECT. If the rows do not match,
they were changed by another user and an error is handled by the application.
If the rows have not been changed in the meantime, they are then updated
with a very brief lock. With optimistic locking the rows are selected twice
for every update, generating twice the amount of network traffic. On the
other hand, locking time is short and resource contention is minimized.
This approach is not without its risks, however. Let's continue with
the airline example. With optimistic locking, the application reads the
same tables by SELECTing the Aircraft, Aircraft_Seat, and Customers
rows, but it does not use the FOR UPDATE option.
No rows are locked. As I said previously, nobody else is likely to update
the customer row while the agent is using it. On the other hand, it is quite
possible that another agent is booking a different seat on this same airplane
for a different customer.
If one reservation agent is planning to update the airplane row, and another agent is about to update the same row with different data, the first agent might have his or her data change stepped on by the second agent. This is the well-known "lost update" problem, which is supposed to be addressed by row-level locking. Unfortunately, as you can see, large-scale row-level locking can be a performance obstacle. In addition, if you do not lock the seat table row, you could lose the reservation altogether. Of course, I trivialized an application example for the sake of illustration; a real airline reservation system is considerably more complex and precarious to design and manage.
Designers need to consider the nature of their transactions - those units of work - and minimize contention. One way to avoid problems is to design the application so that a minimum number of tables require concurrent row locks. This is not easy to do, and you need to perform a lot of careful analysis for anything other than a simple application.
Generally, it is a good idea to keep the length of transactions as short as possible. Regardless of the choice of pessimistic or optimistic locking, the less time from the beginning to the end of a transaction, the better off your application will be. The less time that passes during a transaction means either less chance of another user updating a row and pulling the rug out from under your feet (in the case of Oracle's "snapshot too old") or less likelihood that one transaction will lock out another update transaction (in the case of Sybase/SQL Server's page-level lock and block).
If it is possible for a given application design, try to keep all of
the code for a transaction (from the first SQL statement to either the COMMIT
or ROLLBACK) within one section of logic, one that is
not subject to a user-generated interruption. In an event-driven application, this means that all of this code would exist within one event as a single, continuous stream of logic. Of course, this is not always possible, but the worst-case scenario is to have SQL statements splattered over many windows in a design that is too complex to clearly understand. In complex applications, there is a greater chance that a user action will result in untracked locks that either block other users or cause mysterious slow response times.
With respect to choosing between optimistic or pessimistic locking, application developers do not always have much choice. Many client/server database servers and/or development tools have one approach or the other baked in. Using the alternate method can be difficult, if not impossible. PowerBuilder, for example, assumes that the designer will use optimistic locking. The generation of SQL to handle the multiple SELECTs and the associated row-comparison logic is automatic. You can override this logic by creating your own SQL, but then the convenience and power of PowerBuilder's DataWindows is obviated. If you prefer optimistic locking, however, PowerBuilder offers a quality solution.
For all of the pages and words I have generated in this three-part series, I've barely scratched the surface of application tuning. When I began research on this series last year, I thought I would be writing a brief treatise on bind variables. But the more I dug into the topic, the more information I realized needed to be discussed. As I mentioned in the beginning of Part 1, much is acknowledged about the importance and potential impact of application tuning, but little has been written about the topic. I hope that this series has at least sparked the imagination of application developers and DBAs alike. By no means do I suggest that I have given the topic adequate consideration. My hope is that I have initiated a dialogue among Oracle professionals to further define this topic and to offer some approach to a definitive application tuning methodology. To that end, I sincerely welcome your comments and criticism.
Roger Snowden is a database administrator with LAB-InterLink Inc., a firm based in Omaha, Nebraska, specializing in clinical laboratory automation. Roger welcomes comments; you can email him at [email protected].