Getting Physical with Oracle
Gary E. Sharpe
Commonly ignored physical-placement issues can dampen Oracle performance as the database grows
Optimal physical placement is a prerequisite for Oracle performance in mid- to large-size applications because disk performance is not improving. VLDB storage should no longer be seen simply as bulk logical gigabytes; each disk's mechanical latencies exceed other I/O processes by three to four orders of magnitude. Therefore, the DBA is forced to mask these latencies, effectively making them invisible to applications. This goal is achieved through "optimal physical placement" of database entities. Unfortunately, physical placement tuning involves a never-ending cycle that is the most difficult, time-consuming part of maintaining performance in midrange to high-end Oracle databases. So this process is often triggered as a reactive exercise in response to a performance crisis.Experienced Oracle DBAs stripe active entities to multiply read/write bandwidth. They also keep related tables, indexes, redo logs, swap files, and so on separated for parallel access. This task is not much of a challenge for a modest system with few entities and disks, but difficulties expand geometrically as database size exceeds 20GB or so.
As a database grows, its components are often haphazardly placed on existing drives wherever space is available. This approach leads to hot spots (overloaded disks), which are hard to detect and impossible to predict. Even worse, the effect of a single hot spot in a disk-striped environment can spread to affect many entities, reducing the whole system's performance. When the dynamics of workshifts, changing application mix, and load growth are considered, even the term "optimal" loses meaning. When dozens or hundreds of related database entities must be optimally placed on a large disk farm, the number of possible combinations makes trial-and-error methods inadequate because the solution is difficult to visualize.
In this article, I'll take on often-ignored issues affecting database server performance, discuss what is required to make disk latency invisible, and explain the three levels of the placement conundrum.
Database Growth
The Oracle database and ancillary product suite are being developed so quickly that they lack important capabilities that would make them easier to use, manage, and tune for performance. Furthermore, the average size of enterprise database servers has been growing roughly tenfold every year--10GB was considered a VLDB by Oracle users in 1993, but terabyte projects are almost common in 1997.
This trend is accelerating. With the launch of Oracle8, the Oracle RDBMS has become enabled for terabyte-class growth, fueling the development of more complex systems of massive scale. Clearly, the question arises: How will these huge systems be managed and tuned for performance?
Growing database administration burdens, combined with escalating complexity and skills requirements, have already created management problems. DBAs are expensive and hard to recruit and retain. Short-staffing and the rigors of supporting 24 3 7 mission-critical applications often lead to DBA "burnout" on the job. A typical DBA may change employers frequently. The most talented ones turn to consulting, where they can work at their own pace and charge two or three times more per hour to firms that would prefer to have them as employees. Efficient management of an Oracle data center--and delivery of high-quality services in the face of DBA retention and recruitment problems--can be a severe challenge for a CIO or IT manager.
Performance Factors
Disks are an increasing performance bottleneck. As server disk farms mushroom in size, the relationship between logical database structure and the physical devices on which it resides looms an issue in Oracle tuning because disk technology is not improving in ways that benefit database performance.
According to Moore's Law, microprocessor performance doubles every 18 months. Performance of scalable parallel architectures, combining multiple processors, is growing much faster. Databases, however, reside on disk drives, to which Moore's Law clearly does not apply. Disks are bigger, and the cost per megabyte has plummeted, but they are not getting significantly faster.
Disk-performance development is always constrained by mechanical rotational latency and seek time. Disk drives have moving parts, and mechanical motion takes time. In any active system, it is typical to find high-performance computing resources idling, waiting for the mechanical components to seek, rotate, and find the information requested by a process. Disks involved in one step of a process must often wait for other disks accessing data for another step. Figure 1 shows that nearly all the time taken to execute a single physical I/O is consumed in mechanical delays. The faster I/O channels now being introduced don't help at all.

RDBMS I/O vs. physical I/O activity. The normalized structure of an RDBMS means that a single logical transaction can generate a large number of functionally related reads and updates at the database entity level. Each of these in turn will generate multiple physical I/Os in the disk farm. An OLTP request may trigger hundreds of physical I/Os, while a database query may initiate tens of millions in returning a result. Obviously, if latencies are not masked--and therefore allowed to accumulate at random--their impact will result in poor performance.
Logical view, physical issue. In contrast to the traditions of the mainframe era, physical placement is an abstract concept in the open-system world. DBAs, their development and management tools, and the Oracle database all view storage as merely bulk logical gigabytes; the only physical parameters usually considered are "capacity used" and "capacity remaining." DBAs rarely give thought to where database components are stored and how that storage may affect performance. When a DBA performs space management, it is entirely within the logical structure of the database. Volume managers were designed to make it easier to forget about the physical world by allowing logical entities to extend transparently across physical devices.
Clearly, if physical placement is ignored, and mutually active database entities are located simply where free space is available, conflicts, hot spots, and queues can be expected to occur randomly and dynamically within the disk farm. The only clue to their existence will be flagging performance, usually reported by the user group--obviously, not the preferred outcome.
Placement Tuning
In the late '80s, hardware vendors began to borrow parallel processing techniques from scientific supercomputing to meet the growing demand for higher performance. A parallel architecture is superior to a traditional single processor because the workload is divided into multiple simultaneous processes for faster execution. The same technique is used to speed access to disk storage. When additional capacity or performance is needed, the architecture is scaled by adding additional resources to those already in place, allowing for more parallel processes to occur simultaneously. Performance can be doubled, for example, simply by doubling the number of processors or disks.Unlike software, which can be tweaked to improve performance, a disk drive is a mechanical device subject to real physical limitations. A disk that performs one read operation every 20 milliseconds is never going work any faster than that. If a particular database query requires 25 read operations from that particular disk, then it is impossible for that query to be answered in less than half a second.
An efficient database is therefore organized across many disks. Here lies the essence of optimal placement tuning: Because individual disk I/O operations cannot be accelerated, data should be organized on available disk resources to parallelize access to mutually active entities.
A direct consequence of the notion of placement tuning is that disk capacity should no longer be considered simply as bulk logical gigabytes of available storage. Adding a new drive to a disk farm not only increases the amount of data it can hold, but also (and perhaps more importantly) the number of simultaneous read operations it can carry out. Expanding a storage array with new drives when it is not yet "filled" in the classic sense may seem wasteful, but the increase in performance realized when data is striped across these new drives may very well justify their cost. To a DBA, storage capacity is not exhausted when the server can hold no more data, but rather when it can no longer deliver acceptable productivity.
Disk size and density. Another often overlooked fact is that the development thrust of disk and storage manufacturers is to drive down the cost per gigabyte by increasing areal density. This goal contradicts that of the DBA responsible for performance tuning. Five years ago, 2GB drives featuring 10 to 15 millisecond latencies were the norm. Now 23GB drives are here--offering more than 10 times the capacity at nearly the same unit cost (and unfortunately with little improvement in device performance).
It's great for the budget, but there's a real problem in basing purchasing decisions solely on cost. For a given database size, the number of disks is reduced by a factor of 10, and so is the opportunity for optimal physical placement tuning. Think about it: A 200GB platform using 2GB drives has 100 devices across which to parallelize the I/O load, while the same system with 23GB drives will have only 10 devices.
In an RDBMS, where a single transaction generates a large number of I/O operations to multiple files, the only way to mask mechanical latencies in disk drives is to attempt to place entities in a way that optimally enables mutually related I/O operations to occur simultaneously in parallel. To do this effectively, you need as many disk devices as you can afford.
Optimal placement is critical, but difficult. In a typical enterprise installation, the logical storage components of an Oracle database often number in the hundreds, and must be carefully positioned on the disk farm according to their mutual activity as driven by application programs. Possible combinations may number in the tens of thousands, but only a few may be judged near-optimal. The placement solution typically defies human capacity for visualization in terms of the sheer magnitude of possible placement alternatives.
For example, simultaneous access to multiple application-related entities--which are inappropriately placed on a single disk drive--is a root cause of disk overload. Relocating entities to relieve a hot spot may only create others. A DBA may try to improve performance with costly system upgrades, or waste resources on expensive trial-and-error placement, when the real problem is undetected hot spots that are generating transaction queues, making system resources (and users) wait for access. The system is prevented from delivering its full potential capacity.
The placement tuning conundrum comprises three levels of increasing complexity: striping of database entities across several disks, distribution of mutually active entities, and distribution of sets of mutually active entities relative to the activity of the set. Each of these levels contributes to latency masking (as well as read/write bandwidth) and all are interrelated.
Disk I/O performance may be scaled in a near-linear ratio to number of disks by distributing data for parallel access, as shown in Figure 2 (page 63). Such parallelization also masks device latency. In this simple example, access throughput between the processor and storage is theoretically multiplied by five times, when the database is striped over five disks instead of one. A file that is striped in this manner is often called a "plex"; a group of disks containing one or more plexes is called a "stripeset."
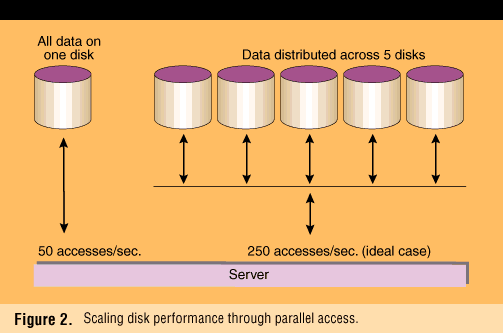
The benefits of striping are, however, gained at the expense of added complexity in entity placement. The opportunity for conflict among entities increases when those entities themselves are distributed.
Level 2: distribution of mutually active entities. An Oracle database is a collection of data that is treated as a unit. Oracle manages the storage and retrieval of related data. The database has logical and physical structures. Logical structures include tablespaces, schema entities, data blocks, extents, and segments. A database is divided into logical storage units called tablespaces. A tablespace is used to group related logical structures. Usually, a database is logically divided into one or more tablespaces. One or more data files are explicitly created for each tablespace to physically store the data of all logical structures in a tablespace.
The logical schema includes entities such as tables, indexes, views, clusters, sequences, stored procedures, synonyms, and database links. There is no relationship between a tablespace and a schema; entities in the same schema can be in different tablespaces, and a tablespace can hold entities from different schemas. A table is the basic unit of data storage in a database. Indexes, clusters, and hash clusters are types of optional structures associated with tables, which can be created to enable access and increase the performance of data retrieval.
Every Oracle database has a set of two or more redo log files. The set of redo log files for a database is collectively known as the database's redo log. The primary function of the redo log is to record all changes made to data. All changes made to the database are therefore recorded in the redo log so that transactions that would otherwise be lost can be recovered in the event of a failure.
Because the entities in a tablespace are related, a single query from a user may generate access activity in all or most of them simultaneously. In fact, a single user entry could cause 50 to 100 disk accesses to occur, involving several dozen entities (tables, indexes, logs, and so on) solely for the purpose of storing a transaction and securing its integrity. In the worst case, if the entire tablespace resides on one disk, access requests will queue, generating an activity hot spot and a costly delay in servicing a customer request for a record. In a chronic situation, an unsuspecting IT manager may be prompted to try a costly but unnecessary system upgrade to improve performance when the problem is really bad placement.
Consider the case of an unrealistically simple Oracle database stored on a single disk, as shown in Figure 3 (page 63). Only five entities appear, although any actual database would have many more. A user entering a transaction to update the database, perhaps upon receiving a customer order, generates activity in all entities simultaneously. Normalized transaction data are stored in Table 1 and Table 2. Intermediate results of this process are written to and read from temporary storage in the temp file. Finally, a copy of the transaction is stored in the log file so that the database can be reconstructed by rerunning transactions in the event of failure.
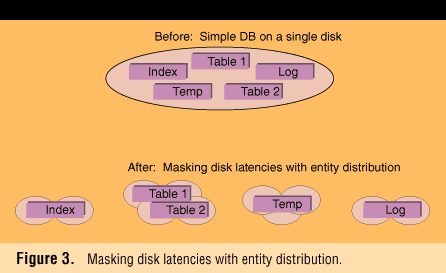
The problem here is that a single device can perform only one read or write operation at a time, and I/Os will queue, causing the entire system to be paced by the mechanical latencies of the disk. If the disk can perform 50 I/Os per second, and a single transaction generates 50 I/Os, the best it can do is one transaction per second. If 10 users share the database simultaneously, the queue can extend to many seconds when they are contending for access.
The fix for this problem is to distribute the components of the database over additional disks. If four disks are used, as shown in the "after" illustration in Figure 3, the system can theoretically perform four parallel I/Os simultaneously, reducing service time to one-quarter that of a single disk. The cost of additional disks is probably easily offset by the value of enhanced performance.
Combining techniques. To accelerate database performance further, the two levels of placement discussed so far can be combined by also striping individual entities as shown in Figure 4 --assuming there are enough disks to do so. In this case there are 11 disks, and each entity has two to four disks dedicated (perhaps unrealistically) to its sole use.
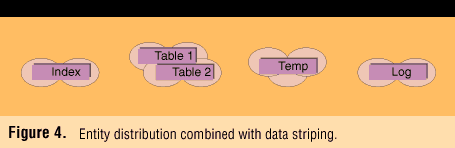
Consider the example in Figure 5 ; this time a 5GB database is stored on a moderately sized array of 24 disks. The total available remaining storage capacity is 45GB after subtracting that already used by this database. For performance purposes, the entities are well-striped and optimally placed so that access is parallelized, load-leveled, and entity activity will not conflict--at least as far as this database is considered in isolation. Only 10 percent of the available disk resources have been used.
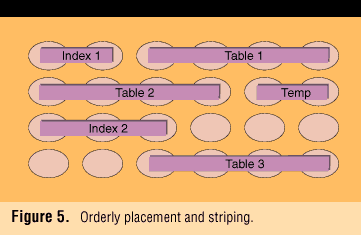
Field experience suggests that orderly placement tends to be the exception in actual practice. Under conditions of growth, habit, and expediency, DBAs tend to place data wherever space is available. Some consideration may be given to whatever else is resident on selected disks, but this becomes extremely difficult to do when entities are striped for performance and are more than very few in number.
A tough situation is made worse by changing workshift loads and application growth. Haphazard placement is the result simply because there is no way to visualize the right layout or time available to search for it. Figure 6 shows an example of how simply using available space can offset any performance gained through striping data.
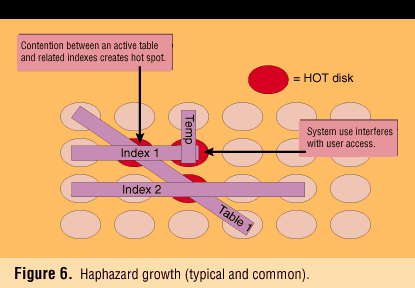
Level 3: distribution of sets of mutually active entities. In nearly every case, several databases share the resources of an application server. Each of these databases has a load and activity profile that may change from hour to hour. Queuing delays can result when entities related to two or more heavily loaded applications are mistakenly made physically coresident.
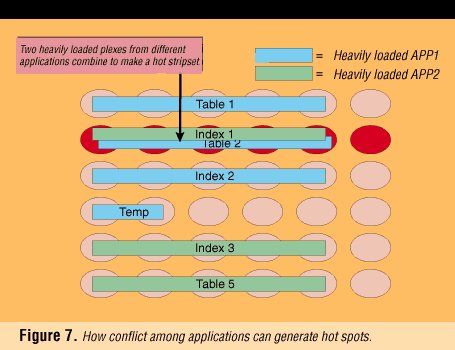
Figure 7 shows an example in which a busy Index 1 from Application 2--although wisely placed separate from its related Table 5--is placed coresident with an active Table 2 from Application 1, which the DBA has thoughtfully placed separate from its own Index 2. In spite of proper placement within individual databases, conflict is inevitable. At the same time that queuing delays are building on the second rank of disks as shown, other disk resources may be underloaded. The relocation plan is clearly seen in the example, but the problem, its solution, and many others like it can easily remain hidden and unaddressed in actual systems supporting realistic numbers of entities.
There are two cases where partitioned tables can offer increased performance. Both cases rely on newly added intelligence to the Oracle query processor, which is now "partition aware." First, the query processor detects when a query relies on data from a subset of the partitions that make up a table. The query processor will not query partitions that would not contribute to the result. This results in less I/O on the disk drives where the active partitions reside.
Other advantages are possible. Oracle8 currently supports partitioning based on ranges of values. Consider a table that is partitioned by date and in which the most recent data is much more likely to be queried than data more than 18 months old. In this case, the partitions containing the most recent data could be placed on the fastest disk drives, and the older data could be placed on slower devices.
The second case in which the new query processor offers performance benefits is when parallel queries of each partition in a table are performed as a table scan. This approach tends to reduce the I/O bottleneck provided that the partitions are placed on separate disk drives. I/O is then distributed and a performance benefit results due to parallelized access.
Table partitioning does not replace the kind of disk striping and placement methodology discussed here, which provides general performance enhancement across the board. Partitioning provides performance gains in a special set of circumstances, and should be seen as providing a new dimension of opportunity for physical placement.
Partitions, however, add a level of increased complexity to placement. In deciding how to best to split a table during its creation, the DBA must have a good understanding of the available storage configuration and volume manager operation in order to make the best use of disk resources. It's easy to make the mistake of partitioning a table onto individual disks instead of striping the whole table onto a disk stripe.
For example, if a table of four sales regions is partitioned by region, then an OLTP system would find itself dependent on only one disk for all the I/O of a region. The east coast, for example, would be the only active region in the morning and the I/O bandwidth of all the other disks would be unused. This problem extends to partitions based on dates. Similarly, archival or aged data should not reside on dedicated disks since their bandwidth will not be available to contribute to access performance of current data.
Challenges Ahead
Although physical placement is key to performance in today's larger database servers, getting there still poses a number of challenges. Database software and the associated application suites are advancing at an unprecedented pace, so quickly that performance management and tuning capabilities haven't kept pace. In-depth placement tuning is a labor-intensive process currently performed by expert DBAs and consultants, professionals whose skills are much in demand. There is a gap to be filled, so we can expect to see major database and third-party tools suppliers address various aspects of performance management with new capabilities and tools.It is clear that both technology advances and business needs will continue to drive the exponential growth of databases. Appreciating the factors that influence database server performance and applying principles of sound physical placement can help you cut the performance-tuning challenge down to size.
Gary Sharpe is president of Bedford, Mass.-based Terascape Software, a developer of computer-assisted placement-tuning and capacity-planning automation products for Oracle databases. You can reach him at [email protected].
This is a copy of an article published @ http://www.oreview.com/