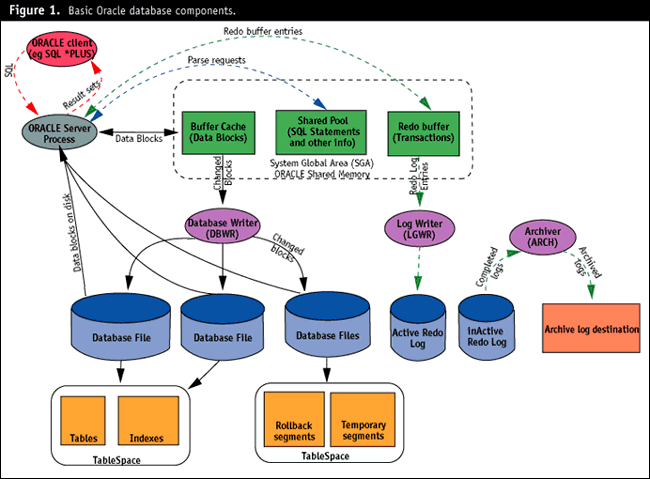
Most Oracle performance specialists agree that sound application design and tuning of application code--including SQL--is the most effective path to high-performance Oracle systems. However, when the application is well-designed and finely tuned, the Oracle server itself can become the limiting resource, so proper configuration and tuning of the server becomes critical to achieveing overall performance requirements. Tuning the server may also be your only option when tuning the application is impossible or impractical.
In the next series of articles, I'll provide a review of Oracle server configuration and tuning issues. In this first installment, I'll discuss how configuring a hardware platform will meet your application's needs and as well as how to build a new high-performance Oracle instance.
rollback command is issued.
Determining memory requirements.. Ensuring sufficient free memory on your host computer is essential for maintaining reasonable performance levels. In most operating systems, memory requirements can be calculated using the formula memory = system + (# users * user_overhead) + SGA + (# server_size). Here are what the terms in the formula mean:
Estimating disk devices.Estimating number required;. A major aim of configuring an Oracle server is to ensure that disk I/O does not become a bottleneck. While there may be some differences in the performance of disk devices from various vendors--especially if the devices are in some sort of RAID configuration (discussed in detail later)--the major restraining factor on disk I/O is the number of disks acquired and the spread of I/O across these devices.
If possible, estimate the physical I/O that will be generated by your database, and use this figure to determine the number of devices that would be required to support the configuration.
How many disks are required for data files? As a simple example, consider a
transaction processing system in which 99 percent of the transactions are
get row, update row, and commit. The peak
transaction rate has been specified at 50 transactions per second.
We know that we will be using an index lookup to retrieve the row, which will require three or four index block lookups (index head block, one or two branch blocks, and one leaf block) and one table-block lookup. Therefore:
I/Os required to fetch row = 4.5
We will use the FOR UPDATE clause to lock the row as it is
retrieved. This will require a further I/O to update the transaction list in the
block itself and an I/O to update the rollback segment:
I/Os required to lock row = 2
Updating the row using the ROWID or current of
cursor will require an I/O to update the block and the rollback segment:
I/Os required to update the row = 2
Committing the row will involve an I/O to the redo log, but because the redo log should be on a dedicated device, we can overlook that I/O when while we calculate datafile I/O. The total number of datafile I/Os for our transaction would appear to be about 8.5 (4.5 + 2 + 2). To be safe, let's double that estimate to account for overheads and special circumstances (data dictionary reads, chained rows, and so on) and allow 17 I/Os per transaction.
We expect Oracle's buffer cache to allow many of our I/Os to be satisfied in memory without requiring a disk I/O. Eighty percent is at the low end of hit rates in the buffer cache, so we'll assume that disk I/Os will be about 20 percent of "logical" I/Os. Remembering that our peak transaction rate is about 50/second, we can estimate that datafile I/O will be:
Disk I/Os per second = 17 * 20% * 50 = 170
Disk capacities vary, but disk in common usage can perform 20 random I/Os per second reasonably comfortably and as much as 50/second in bursts. Using the figure of 20 I/Os per second, we expect to require as many as 170/20 = 8.5 disk devices, and to spread our data evenly across these devices in order to comfortably satisfy database file I/O.
The number of disk devices available to your database determines the maximum I/O rate. Try and calculate the likely I/O rates and use these rates to estimate the number of disk devices required by your application. Redo logs should be on a dedicated device if there is significant update activity
RAID.RAID is an increasingly popular way of delivering fault-tolerant, high-performance disk configurations. There are several levels of RAID (see Table 1) and a number of factors to take into consideration when deciding on a RAID configuration. Three RAID levels are commonly provided by storage vendors:
| Situation | RAID 0 | RAID 1 | RAID 0+RAID 1 | RAID 5 |
|---|---|---|---|---|
| Database files are subject to high read activity | Database files are subject to high write activity | Redo logs | Protection from media failure | Disk overhead (amount of addition disk required) |
| Good performance | Good performance | Striping is of limited benefit because I/Os are all sequential | None | None |
| Unless datafiles are striped across disks using Oracle striping, disk bottlenecks may result | Unless datafiles are striped across disks using Oracle striping, disk bottlenecks may result | Good performance | Yes | 100% |
| Good performance | Good performance | Striping is of limited benefit since I/Os are all sequential | Yes | 100% |
| Good performance | Poor performance because the parity block and the source block must both be read and updated | Poor performance because the parity block and the source block must both be read and updated | Yes | Varies depending on the number of devices in the array but usually 20-25% |
RAID 0 and RAID 1 are commonly combined. Such striped and mirrored configurations offer protection against hardware failure together with spread of I/O load.
RAID 0 and RAID 5 improve the performance of concurrent random reads by spreading the load across multiple devices. However, RAID 5 tends to degrade write I/O because both the source block and the parity block must be read and updated. It should never be used for Oracle redo logs, but it can be used for data files if the database has a high-read/low-update profile. Neither RAID 0 nor RAID 5 offer any performance advantages over single-disk configurations for sequential reads or writes.
The performance of RAID 0+1 for database files and RAID 1 for redo logs is generally superior to any other configuration and offers full protection from media failure. However, RAID 5 requires less disk than RAID 0+1 and may provide acceptable performance in many circumstances.
Battery-backed caches in RAID devices. The write penalty associated with RAID devices, and with disks in general, can be reduced by the use of a nonvolatile cache. The nonvolatile cache is a memory store with a battery backup that ensures that the data in the cache is not lost in the event of a power failure. Because the data in the cache is protected against loss, the disk device can report that the data has been written to disk as soon as it is stored into the cache. The data can be written down to the physical disk later.
If you're considering a RAID 5-based solution, give preference to RAID arrays that are configured with a nonvolatile cache. Such a cache can reduce the write I/O overhead associated with RAID.
CPUs. While we can estimate disk and memory requirements fairly accurately before a system is built, it is far more difficult to accurately estimate an application's CPU requirements. The CPU requirements for an Oracle database server will be determined by operating system, hardware, database I/O rates, and the frequency and types of transactions.
Because CPU requirements are so hard to estimate, you could use some of the following methods to arrive at a suitable CPU configuration:
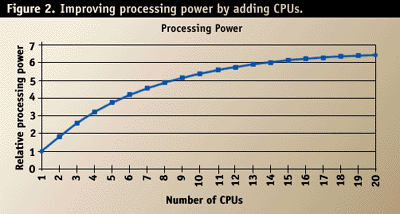
Improvement gained by adding more CPUs. As more CPUs are added to a SMP machine, the overhead of coordination among multiple CPUs increases (see Figure 2). This means that a diminishing return is obtained as more CPUs are added. Moving from a single CPU to two CPUs may nearly double processing capacity. However, moving from four to eight CPUs might result in only a 50 percent improvement.
Because of the scalability deficiencies of multi-CPU systems, it is better to have a smaller number of more powerful CPUs than to have a large number of less powerful CPUs. Don't assume that doubling the number of CPUs will double the processing capacity.
Database block size. The database block is the smallest unit of Oracle storage. Data files, buffer cache entries, tables, and almost all Oracle structures are composed of database blocks. The size of the database blocks is set when the database is created and cannot be changed unless the database is re-created.
Oracle recommends that the database block size be set to a multiple of your operating system block size. However, the default value (2K on many systems) is often substantially less than the block size used by the operating system.
For a high-performance database system, ensure that the database block size is at least the size of the operating system block size. Because operating system I/O on partial blocks can be very inefficient, it might actually be slower to process a 2K block than an 8K block if the operating system block size is 8K. On many Unix operating systems, the operating system block size is 8K; on Windows NT, the block size is usually 2K or 4K.
Increasing the block size beyond the operating system block size will be most beneficial for applications that frequently perform full table scans as the number of I/Os required to scan the table may be reduced. For OLTP applications, smaller block sizes (but not usually below the operating system block size) are recommended, because most table accesses will be via an index that will only be retrieving a single row.
Redo log configuration.. When a transaction is committed, a physical write to the redo log file must occur. The write must complete before the commit call returns control to the user, hence redo log writes can provide a limit to throughput of update-intensive applications.
Redo log I/O will be optimized if the log is on a dedicated device and there is no contention for the device. If this is achieved, then the disk head will already be in the correct position when the commit is issued, and write time will be minimized. (The disk won't need to "seek.")
Because the log writes are sequential and are performed by logwriter processes only, there is little advantage to striping. Because logwriter is write-only to these devices, the performance degradation caused by RAID 5 is likely to be most significant, even if the volume is dedicated to redo logs (because of contention with the archiver process).
To ensure against any loss of data in the event of a media failure, it is essential that the redo logs be mirrored. Oracle provides a software mirroring capability (redo log multiplexing), although hardware mirroring (RAID 1) is probably more efficient. To maximize transaction-processing performance, locate redo logs on a fast, dedicated disk device.
Because switching between redo logs results in a database checkpoint, and because a log cannot be reused until that checkpoint is completed, large and numerous logs can result in better throughput. By increasing the number of logs, you reduce the possibility that a log will be required for reuse before its checkpoint is complete. By increasing the size of the logs we reduce the number of checkpoints that must occur.
The optimal size for your redo logs will depend on your transaction rate. You will want to size the logs so that log switches do not occur too rapidly. Because you will usually have allocated dedicated devices for redo logs, there probably will be substantial disk capacity available for logs; it's often easiest to overconfigure the log size and number initially. Log sizes of 64 to 256MB are not uncommon; configuring 10 to 20 redo logs is also not unusual.
Optimizing archiving. Archived logs are copies of online redo logs that can be used to recover a database to point of failure or other point in time after a backup has been restored. Archive logging is also required if online backups are desired.
Once a redo log file is filled, and Oracle moves to the next log file, the ARCH process copies the recently filled log to an alternate location. If the archiver reads from a log on the same physical device as the current log being written, the sequential writes of the logwriter will be disrupted. If the logwriter falls sufficiently behind, the database may stall because a log file cannot be reused until it has been archived.
It is therefore important to optimize the performance of the archiver. Contention between the archiver and the logwriter can be minimized by alternating redo logs over two devices. The redo log writer can then write to one device while the archiver is reading from the other device. Because the archiver must be capable of writing at least as fast as the logwriter, the archive destination should either be a dedicated device or a dedicated set of disks in a RAID 0+1 (mirrored and striped) configuration.
If you're running in archivelog mode in a high-update environment, allocate an additional dedicated device (total of two) for the redo logs and a further dedicated device (or devices) for the archive destination.
Optimizing data file I/O. Oracle server processes read from database files when a requested data item cannot be found within the Oracle buffer cache. Waiting for data from disk is one of the most common reasons for delays experienced by server processes, so any reduction in these delays will help improve performance.
Writes to the database files are made on behalf of the user by one or more DBWR processes. These I/Os are random in nature. Although user processes do not wait for DBWR to complete its writes on their behalf, if DBWR falls behind, the Oracle buffer cache will fill up with "dirty" blocks and waits will occur when user processes try to introduce new blocks into the cache.
Optimizing datafile I/O can be achieved by getting a good hit rate in the buffer cache, striping data files across a sufficient number of disks, and optimizing database writer performance
Buffer cache hit rate. If a data block requested for read is already in the buffer cache then a disk read will be avoided. Avoiding disk reads in this manner is one of the most significant ways to optimize an Oracle database. In the next installment, you'll see how to monitor database hit rates. If the hit rate is low, or the absolute number of disk reads too high, then increasing the size of the buffer cache can significantly improve disk performance.
Striping. At the beginning of this installment I explained how the ultimate limit on I/O performance is dictated by the number of devices and the spread of data across these devices. You should first ensure that a sufficient number of disks will support your projected I/O rates. You should also ensure that data is spread as evenly as possible across these disks and that there are no disk "hot spots."
There are three ways to spread data across devices: RAID 0, RAID 5, or Oracle striping. Remember that RAID 5 can decrease write performance unless the RAID array is associated with a battery-backed memory cache--and quite often even then. Generally, RAID 0 is recommended on performance grounds. If RAID 0 is unavailable, you should manually stripe your tablespaces across multiple devices. Manual or "Oracle" striping is achieved by allocating many small files to each tablespace and spreading these files across the multiple disks.
Because a table extent must be located within a single database file tables consisting of a single extent will not be able to be manually striped. In this case, you will probably want to ensure that heavily used tables (and indexes) comprise many extents. You may wish to reduce the size of your data files to that of a single extent (plus a one-block overhead).
Optimizing database writers. The DBWR is the only process that writes modified database blocks from the buffer cache to the database files. The best way to optimize the database writer throughput is to spread I/O across multiple disk devices and allow the database writer to write to these disk devices in parallel.
Parallelizing database file writes can be achieved in two ways: Multiple
database writers can be configured using the DB_WRITERS configuration parameter,
or operating system asynchronous I/O or list I/O can be enabled. This will allow
the database writer to issue write requests against multiple disk devices
simultaneously.
Experience shows that operating system asynchronous I/O performs more efficiently that multiple database writers. However, asynchronous I/O may not be available on all platforms or may require special measures. In some operating systems, asynchronous I/O may require that the database be built on raw devices.
If configuring multiple database writers, you may benefit from configuring as many database writers as you have physical disks.
Guy Harrison is an independent Oracle consultant specializing in Oracle development and performance issues. This article was extracted from his book Oracle SQL High-Performance Tuning (Prentice Hall, 1997). You can contact Guy at [email protected] or at http://werple.net.au/~gharriso.