
A Guide to Oracle Performance Tuning, Part 2
Guy Harrison
Part 2 picks up on Guy's previous discussion of initial database configuration and then launches into server monitoring and tuning.
In the "A Guide to Oracle Performance Tuning, Part 1," I proposed several principles for configuring an adequate hardware platform for your application and Oracle instance. I also started to establish guidelines for configuring a new Oracle system for optimum performance. In this installment, I'll conclude my coverage of initial database configuration and begin an examination of Oracle server monitoring and tuning.
Tablespace Design and Extent Sizing Policy
Tablespaces should be used to group objects with similar storage and access requirements. From a performance point of view, it is important to store objects with similar extent sizes and growth patterns together to avoid the fragmentation that leads to performance degradation and database failures.
The following tablespaces should be created as standard practice:
- The
SYSTEM tablespace contains objects owned by SYS (mainly data dictionary tables).
- The
TOOLS tablespace contains objects created and used by development tools such as SQL
- Forms. In general, objects in this tablespace should be owned by
SYSTEM.
- The
ROLLBACK tablespace contains rollback segments only. Rollback segments can grow and contract, so it's important that they be placed in their own tablespace so that free space does not fragment or get used up by other objects.
- The
TEMPORARY tablespace contains temporary segments created by disk sorts and intermediate results sets.
- The
USER tablespace can create ad hoc tables created by users. These might include temporary tables explicitly created by programs.
When these standard tablespaces have been created, we can move onto creating tablespaces to hold application data.
There is a strong argument for arranging objects into tablespaces based on uniform extent sizes. In this scheme, all objects in a tablespace have extents of the same size. This requires that the tablespace be defined with the default initial extent size equal to the default next extent size and pctincrease set to zero. Segments (tables, indexes, and so on) never specify extent sizes in their create statement, but always adopt the default storage for the tablespace.
The advantage of this uniform extent sizing policy is that it completely eliminates free-space fragmentation within your database. This fragmentation occurs when tables with varying extent sizes are stored together. When an object is dropped (perhaps to be rebuilt), irregular areas of free space are created. Eventually, all the free space in the tablespace will comprise fragmented, unevenly sized pockets. When an object needs to create a new extent, it has to scan these pockets for a suitably sized fragment. If one cannot be found, it must coalesce adjacent pockets. If a suitably sized area of free space still cannot be found, the segment will fail to extend.
If every extent in the tablespace is the same size, the problems of free-space fragmentation will never occur; every extent in the free space will be reuseable and you will be able to drop and rebuild database objects without risking tablespace degradation. This will improve performance when objects extend and give you more freedom to rebuild objects as a tuning measure (to create multiple free lists or eliminate chained rows, for example).
To implement a standard extent sizing policy, perform the following steps:
- Determine the number of tablespaces. Usually at least six will be required
(SMALL_TABLE, MEDIUM_TABLE, BIG_TABLE, SMALL_INDEX,MEDIUM_INDEX, BIG_INDEX).
- Estimate the sizes for all your tables and indexes.
- Assign an extent size to each tablespace. This will probably be an estimate that you will later refine.
- Allocate tables and indexes to the appropriate tablespace. An object is in the correct tablespace if there is not too much wasted space (for example, a 50K table in a tablespace with 50MB extents) and if the table will not require too many extents.
- Vary extent-sized and object allocations until all objects are in an appropriate tablespace.
One controversial aspect of the uniform sizing policy is that it leads to some objects having a large number of extents. In the past, Oracle recommended that objects be maintained in a single extent to optimize scan performance. However, more recent research has shown that in the modern Oracle environments multiple extents cause only a marginal performance degradation at worst, and may actually improve performance in some cases by spreading I/O.
Rollback Segment Configuration
The configuration of your rollback segments can have a important effect on the performance of your database, especially for transactions that modify data. Any operation that modifies data in the database must create entries in a rollback segment. Queries that read data that has been modified by uncommitted transactions will also need to access data within the rollback segments.
Poorly tuned rollback segments can have the
following consequences: If there are too few rollback segments, transactions may
need to wait for entries in the rollback segment; and if rollback segments are
too small, they may grow dynamically during the transaction and shrink later
(if the rollback segment has an optimal size specified).
In addition to these performance-related problems, poorly tuned rollback segments can cause transaction failure (failure to extend rollback segment) or query failure ("snapshot too old"). These guidelines may serve as a starting point for rollback segment configuration in a transaction-processing environment:
- The number of rollback segments should be at least one-quarter of the maximum number
of concurrently active transactions. In batch environments, this may mean allocating
a rollback segment for each concurrent job.
- Set
OPTIMAL or MINEXTENTS so that the rollback segment has at least 10 to 20 extents. This minimizes waste and contention when a transaction tries to move into an occupied extent.
- Make all extents the same size.
- Allow ample free space in the rollback segment tablespace for rollback
segment expansion. Large, infrequent transactions can then extend a rollback
segment when required. Use
OPTIMAL to ensure that this space is reallocated
when required.
It's very difficult to determine the optimal setting for rollback segments by theory alone. Rollback segments should be carefully monitored and storage adjusted as required. In Part 3, we'll discuss ways of monitoring rollback segments.
Temporary Tablespace
A sort operation that cannot be completed in memory must allocate a temporary segment. Temporary segments may also be created to hold intermediate result sets that do not fit in memory. The location of these temporary segments will be determined by the temporary tablespace clause in the create or alter user commands. You should always allocate at least one tablespace for temporary segments.
Prior to Oracle7.3, a temporary tablespace had the same characteristics as ordinary tablespaces and temporary segments allocated space in much the same way as other segments, such as tables and indexes. An initial extent would first be allocated, and if this was insufficient, further extents would be allocated as required. The size for these extents would be determined by the default settings for the tablespace as determined by the create or alter tablespace commands. Allocating additional extents for temporary segments also often caused contention for the space-transaction lock. As a result, best performance would be achieved by setting the size of extents such that temporary segments would require only one extent.
From Oracle7.3 onward, the TEMPORARY
clause was added to the create tablespace command to explicitly create a tablespace for temporary operations. This tablespace contains a single sort segment that can be used by all sessions. The segment is never deallocated, so the overhead and contention caused by allocating segments and extents are removed.
The extent size in the temporary tablespace
should be at least the same as the memory allocation provided by the SORT_AREA_SIZE
parameter (plus one block for the segment header). Regardless of the Oracle version, the temporary tablespace should be large enough to hold all concurrent temporary segments. If it isn't, errors may be returned to SQL statements that attempt to allocate additional space. It's not easy to predetermine how large disk sorts will be, so it may be necessary to refine your first estimates. You can measure the size of temporary segments using DBA_SEGMENTS (SEGMENT_TYPE="TEMPORARY") in Oracle7.2 and earlier or V$SORT_SEGMENT in Oracle7.3 and later.
Sizing the SGA
The size and configuration of the system global area (SGA) can have a substantial effect on the performance of your database. This is not surprising as the SGA exists primarily to improve performance by buffering disk reads and reducing the need for SQL statement parsing.
It's difficult to determine in advance exactly how large the various components of the SGA should be. In general, oversizing areas of the SGA will not hurt performance as long as the SGA can fit in main memory. So if you have memory to spare, increasing the size of the SGA is usually not a bad idea.
Buffer cache. As we discussed earlier, the buffer cache area of the SGA holds copies of data blocks in memory to reduce the need for disk I/O. The following principles are relevant to the sizing of the buffer cache:
- You aim to size the buffer cache so that sessions rarely need to read data blocks from disk. In general, you should target a "hit rate" of 90 percent or higher, meaning 90 percent of all read requests are satisfied from the cache without requiring a disk access.
- In general, the higher the rate of I/O activity, the greater your incentive to reach a high hit rate. For example, if your logical I/O rate is only 500 reads per second, a hit rate of 90 percent translates into 50 reads/second--a rate that could probably be satisfied comfortably by two disk devices. However, if the logical I/O rate is 5,000 reads/second, the physical I/O rate associated with a 90-percent hit rate will be 500 reads/second, which will probably overtax a disk configuration under 12 disks in size. In this case you might need to aim for a hit rate of 95 percent or higher.
- Applications that perform frequent full table scans of very large tables are unlikely to achieve a good hit rate in the buffer cache.
Adjusting the size of the buffer cache is one of the most fundamental tuning options. You need to ensure that there is enough free memory on your system to allow for an increase if required.
Buffer-cache sizes vary depending on application characteristics and I/O rates. Many applications get good performance from a buffer cache as small as 10MB. High-performance applications may have buffer caches of 50 to 100MB, and caches of over 200MB are not uncommon.
Shared pool. The shared pool is another large and performance-critical area of memory held in the SGA. The major components of the shared pool are:
- The library cache stores parsed representations of SQL and PL/SQL blocks. The purpose of the library cache is to reduce the overhead of parsing SQL and PL/SQL by the caching and sharing of parsed SQL statements.
- The dictionary cache (sometimes called the row cache) caches data dictionary information. The data dictionary contains information about the database objects, users, and other information defining the database. Because the data dictionary is referenced so frequently, it is cached separately in this special area.
- If using the Multithreaded Server (MTS), some user session information, such as
cursor structures, will be stored in the shared pool. This section of the shared pool
is referred to as the User Global Area (UGA).
The size of the shared pool is determined by a
single database configuration parameter (SHARED_POOL_SIZE) and the individual components of the shared pool cannot be sized separately. As with the buffer cache, it's not possible to determine the exact optimal size in advance. You'll have to monitor and adjust the shared pool until the optimal setting is found.
There are several considerations when sizing the shared pool. First, the default value for the shared pool (3.5MB) tends to be too small for many applications. Second, if your application makes extensive use of large PL/SQL stored packages, your shared pool requirements will be higher. And third, if your database will use the MTS option, your shared pool may need to be much larger. The amount of memory depends on the memory allocated for session information and the number of concurrent cursors open by a session. The memory required usually does not exceed about 200K per concurrent session unless large sort areas or hash areas are allocated.
It's not uncommon for shared pools of 50MB or higher to be allocated, although smaller allocations may also be adequate. If MTS is used, shared pools of several hundred megabytes may be required; however, memory allocation for server processes will be reduced by a commensurate amount.
Redo buffer. The redo buffer contains redo entries destined for the redo log, which is flushed either periodically or when a commit occurs. Unlike the other areas in the shared pool, it is unwise to oversize the redo buffer. If it's too large, the logwriter process has to work harder when a flush is required.
Using MTS
Oracle's MTS option allows multiple client programs to share a server process (see Figure 1). Without MTS, each Oracle session will usually acquire a dedicated server process. (Some operating systems, such as VMS, allow user and server processing to occur in the same process if both exist on the same host.) If MTS is enabled, processes can share servers, reducing the overall number of server processes required.
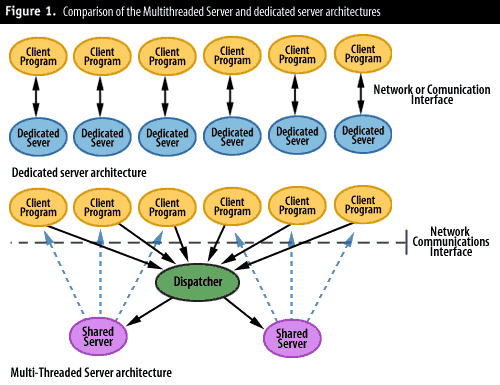
If implemented appropriately, MTS can reduce the overall memory requirements for an Oracle implementation. In some circumstances, implementing MTS may avoid internal bottlenecks by reducing the number of server processes competing for limited resources. However, if implemented inappropriately, MTS can have a negative effect on performance; if user processes must wait for a server or dispatcher process to become available, performance will degrade substantially. So before implementing MTS, you need to answer two questions: whether MTS is appropriate for your application, and what the optimal user-to-server process ratio is.
MTS is suitable for interactive applications because they involve a substantial amount of "think time" while the user assimilates data, decides on a course of action, or is simply busy typing. With these applications, high user-to-server ratios will be possible because server processes will usually be idle. In contrast, applications that are continually busy--such as intensive batch processing or data loads--will tend to consume all the resources of a dedicated server and will not benefit from shared servers.
If you decide MTS is appropriate, the user-to-server ratio will depend on the estimated proportion of time that user processes are idle, at least in terms of database activity. If you expect your processes to be idle 90 percent of the time, you may consider implementing one shared server per 10 users. The number of dispatchers will usually be less than the number of servers--a ratio of one dispatcher per five to 10 servers might be appropriate.
Parallel Server Processes
Another important consideration is the configuration of parallel server processes to support parallel SQL. Parallel SQL can contribute substantially to performance of individual queries. However, many environments are totally unsuitable for Parallel Query Option. For example, a transaction-processing environment is unlikely to benefit from parallel SQL--the transactions probably won't use table scans and parallelism is usually achieved by multiple sessions executing concurrently. However, parallel SQL may still be used in overnight batch processing where a few sessions must perform a great deal of processing in a short time.
Raw PartitionsSee raw partitions;
Under Unix, Windows NT, and some other operating systems, Oracle database files may either be created on file systems (FAT, NTFS, UFS, JFS) or "raw" partitions. Raw partitions allow I/O to go directly to disk, avoiding the buffering of file systems. In Unix, updates to data files on file systems often need to update Unix inodes (a sort of directory entry) as well. Because inodes are often located in the first blocks of the file system, they can become hot spots even when the file system is striped across multiple disks.
Using raw partitions entails a significant administration overhead and complicates database backup and configuration. Some of these disadvantages are alleviated by the use of logical volume management software.
Raw partitions are a controversial topic in the Oracle community, and there is no clear consensus on their use. However, these positions seem fairly well accepted: Where there is no bottleneck in the I/O subsystem, no improvement in application performance will be gained by a switch to raw devices; while for heavily loaded, I/O-bound applications, some improvement in performance will be achieved by the move to raw devices.
Monitoring Operating System Performance
A good place to start when diagnosing a poorly performing Oracle system is at the operating system level. Because the operating system provides key resources such as CPU, memory, and disk I/O, monitoring will be able to detect any shortfall in system resources (such as insufficient memory) or contention for resources (such as a "hot" disk). All modern operating systems provide some form of monitoring that can reveal the use of computer resources. Consult your operating system documentation for a detailed description of these tools.
Memory Bottlenecks
A shortage of available memory on a host computer will usually lead to severe performance degradation. Most host operating systems support virtual memory (NetWare is a notable exception), which allows the memory accessed by processes to exceed the actual memory available on the system. The memory in excess of actual memory is stored on disk. Disk accesses are several orders of magnitude slower than memory accesses, so applications that need to access virtual memory located on disk will typically experience significant performance degradation.
When a process needs to access virtual memory that
is not in physical memory, a page fault occurs and the data is retrieved from disk
(usually from a file known as the swapfile or from the program's executable file)
and loaded into main memory. If free physical memory becomes short, most operating
systems will look for data in main memory that has not been accessed recently and
move it from main memory to the swapfile until sufficient free memory is available.
The movement of data between the swapfile and main memory is known as paging.
The scan rate reveals the rate at which the
operating system searches for memory to page out of the system. Increases in the
scan rate can indicate increasing pressure on available memory. If free physical
memory becomes extremely short, the operating system may move an entire process
out of main memory in a procedure called swapping. Any level of swapping is usually
a sign that memory shortage has reached a crisis point.
Acceptable levels of swapping, paging, and free memory vary among operating systems. However, three principles apply to most of them. First, swapping should not occur. Second, paging activity should be low and regular. And third, sudden peaks of paging activity may indicate a shortage of memory.
There should be sufficient free physical memory for all database processes and the Oracle SGA. Although virtual memory allows the computer to continue operating when all physical memory has been exhausted, the cost in performance terms is usually too high.
If system monitoring reveals that memory resources
are inadequate, two options are available: Acquire additional memory, or reduce Oracle's
memory consumption. Some of the ways memory consumprion can be reduced are:
- Reduce parameters that control the size of the Oracle server processes.
The two main options are
SORT_AREA_SIZE and HASH_AREA_SIZE; these parameters
control the amount of memory allocated for sorts and hash joins. If they're set
unnecessarily high, memory may be wasted.
- Reduce the size of the SGA. The buffer cache or shared pool may be oversized
and wasting memory.
- Reduce the number of server processes by implementing MTS. This can be an
effective way to reduce memory requirements but can backfire if performance
degrades because of contention for the shared servers.
Disk I/O Bottlenecks
Disk I/O bottlenecks are also a common cause of poor database performance.
They occur when the disk subsystem cannot keep pace with read or write requests.
This condition may be recognized by performance metrics such as disk %busy (if a
disk is busy more than 50 percent of the time, I/O requests are probably being delayed) and disk queue length (the number of requests queued against the disk, which should not average more than one or two). If the queue is long but the disk is not busy, the bottleneck may reside in the disk controller rather than the disk itself.
If you suspect that a particular disk
is causing a bottleneck, the action depends on the types of files stored on the disk.
If the disk contains Oracle database files, you should attempt to spread the files
across multiple disk devices. If the disk contains redo logs, ensure that no other
active files exist on the same device. If you're in ARCHIVELOG mode, alternate redo
logs across multiple devices to eliminate contention with the archiver process.
If the disk contains archived redo logs, ensure that there is no process competing
with the archive process for the device; it's common for this device to become busy
in bursts because when a log is archived, it will copy the log to the archive
destination in one operation.
CPU Bottlenecks
In a well-tuned Oracle database, memory and disk resources do not cause a bottleneck. As load on such a database increases, the CPU becomes the critical resource and eventually no further increases in throughput will be possible due to CPU limitations.
In one sense, such CPU bottlenecks are healthy because they indicate that other subsystems are not constraining performance and that all available CPU is used. However, excessive CPU use can also indicate that the application or Oracle is performing inefficiently. Possible causes of excessive CPU requirements in Oracle include:
- Inefficient SQL. SQL that has excessive I/O requirements will not only tax the I/O subsystem but may also heavily load the CPU. This is because most of the overhead of Oracle logical I/O occurs in memory and the manipulation of Oracle shared memory is a CPU- intensive operation.
- Excessive sorting. Sorts can be CPU-intensive. If your application performs frequent in- memory sorts, it may result in a CPU bottleneck. It may be possible to reduce this overhead by eliminating accidental sorts or using indexes to retrieve rows in the desired order.
- Excessive parsing. Applications that discard SQL cursors or that force reparsing by using literals instead of bind variables will make Oracle perform CPU-intensive parse operations more frequently.
If your application is CPU-bound, you have the option of either increasing the amount of available CPU or reducing the demand for it. You may be able to add additional CPUs to your system or to upgrade your CPU to a faster model. Keep in mind that the improvement gains achieved by adding CPUs diminish as more are installed. It is usually better to have faster CPUs rather than more CPUs.
To reduce the CPU requirements of your application, tune the application's SQL and minimize unnecessary reparsing by using bind variables and performing efficient cursor management. If your database server has multiple CPUs, individual processes may become CPU-bound even if the system as a whole is not. Because a single process can only use a single CPU, a single process blocked on CPU will only consume 25 percent of the CPU resources of a four-CPU machine. If you detect or suspect that a process is blocked in this manner, you could try and parallelize the operation--either by using parallel SQL or by parallelizing the application
Recognizing Bottlenecks
Effective operation of the Oracle database depends on an efficient
and unconstricted flow of SQL and/or data among user processes, Oracle processes,
Oracle shared memory, and disk structures; Figure 2 illustrates some of these process
flows. To understand process flows within an Oracle instance, consider this short SQL
transaction, which is illustrated in Figure 2:
select * from employees
where employee_id=:1
for update of salary;
update employees
set salary=:2
where employee_id=:1;
commit;
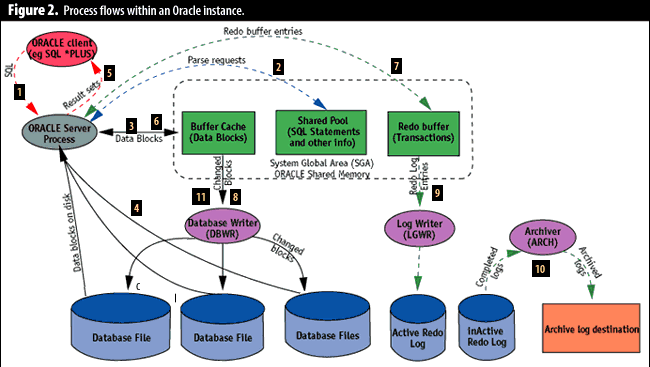
The numbered labels in Figure 2 correspond to these activities:
- The client program (SQL*Plus, Oracle Power Objects, or some other tool)
sends the SELECT statement to the server process.
- The server process looks in the shared pool for a matching SQL statement.
If none is found, the server process will parse the SQL and insert the SQL
statement into the shared pool. Parsing the SQL statement requires CPU and
inserting a new statement into the shared pool requires a latch, an Oracle internal
lock that prevents processes from concurrently updating the
same area within the SGA.
- The server process looks in the buffer cache for the data blocks required.
If found, the data block must be moved on to the most-recently used end of the
Least Recently Used (LRU) list. This too requires a latch.
- If the block cannot be found in the buffer cache, the server process must fetch it from the disk file, which will require a disk I/O. A latch must be acquired before the new block can be moved into the buffer cache.
- The server process returns the rows retrieved to the client process, which may involve a network or communications delay.
- When the client issues the
UPDATE statement, the process of parsing the SQL and
retrieving the rows to be updated must occur. The update statement then changes the
relevant blocks in shared memory and also entries in the rollback segment buffers.
- The update statement will also make an entry in the redo log buffer that records the transaction details.
- The database writer background process copies modified blocks from the buffer cache to the database files. The Oracle session performing the update needn't wait for this to occur.
- When the
COMMIT statement is issued, the logwriter process
must copy the contents of the redo log buffer to the redo log file. The COMMIT
statement will not return control to the Oracle session issuing the commit until
this write is complete.
- If running in
ARCHIVELOG mode, the archiver process will copy full redo logs to the archive destination. A redo log will not be eligible for reuse until it has been archived.
- At regular intervals, or when a redo log switch occurs, Oracle performs a
checkpoint. A checkpoint requires that all modified blocks in the buffer cache
be written to disk. A redo log file cannot be reused until the checkpoint completes.
The goal in tuning and monitoring the Oracle instance is to ensure that data and instructions flow smoothly through and among the various processes and that none of these flows becomes a bottleneck for the system as a whole. Monitoring scripts and tools can be used to detect any blockages or inefficiencies in each of the processing steps previously outlined.
Tuning and Monitoring Tools
To diagnose and remedy server bottlenecks effectively, we need tools that can help us to measure the load and efficiency of the various process flows. The alternatives are tools bundled with the Oracle software, third-party tools, and home-grown and public-domain tools.
Oracle Monitoring Tools. The ultimate source of Oracle instance performance information are the dynamic performance tables (or V$ tables). These are not "true" tables, rather, they're representations of Oracle internal memory structures that can be queried using SQL. These tables contain much information from which significant performance information can be derived. However, using the V$ views directly requires some experience. Oracle Server Manager provides dynamic access to information in the V$ views, but the display is in character mode only and provides little in the way of interpretation.
The Oracle distribution includes a pair of SQL
scripts that can be used to collect useful SQL statistics for a time interval. The
script utlbstat.sql is run at the commencement of the period of interest and the
utlestat.sql run at the end of the period. The utlestat script produces a report on
changes in the values of significant columns in the V$ tables. While this information
can be significant, the report provides little interpretation and reports mainly raw
data.
Oracle provides an optional add-on to the Enterprise Manager known as the Oracle Performance Pack. This product includes real-time graphical monitoring of databases along with analytical and diagnostic facilities. However, as an add-on product, the tool is not always available.
Third-Party Tools. A variety of third-party tools are available for monitoring and diagnosing Oracle performance, including Patrol from BMC (www.bmc.com), DBAware from Menlo Software (www.menlosoftware.com), AdHawk from Eventus (www.eventus.com), and DBGeneral from Bradmark (www.bradmark.com). All of these tools monitor Oracle load, diagnose performance problems, and advise on corrective action. I highly recommend such tools because the native performance monitoring provided by Oracle leaves much to be desired.
Freeware Tools. Because the tools provided with a default Oracle instance are inadequate for detailed performance analysis, and because sophisticated third-party tool sets are often unavailable, many professionals develop their own toolkits for performance monitoring. In this article, I'll use my own "home-grown" SQL*Plus scripts to illustrate performance monitoring principles. You can get a copy of these SQL*Plus scripts from my home page at http://werple.net.au/~gharriso. These scripts collect performance statistics from the V$ tables either for a nominated time period or from the last time the database was started.
Key Efficiency Ratios
Certain key ratios can be used to the database efficiency of database usage.
For example, the buffer cache hit ratio indicates the frequency with which required
blocks are not found in the buffer cache and must be fetched from disk. A low value
indicates an inefficient use of the SGA and potential for performance improvements.
My home-grown db_stA.sql or db_stS.sql scripts can report on these ratios;
Listing 1 shows example output.
Database efficiency indicators:MYDB 8/10/96:15:06
Sampled since database startup at 08/10:01:32:56 |
Ratio (mostly percentages)
-------------------------------
|
Value
----------
|
Comments
------------------
|
| buffer cache hit ratio | 84.0257 | *** May need to increase db_block_buffers |
| dictionary cache hit rate | 95.8915 | *** high dictionary cache miss |
| library cache get hit ratio | 97.9864 | |
| library cache pin hit ratio | 98.6949 | |
| Immediate latch get rate | 91.7468 | *** Poor latch hit rate |
| Willing to wait latch get rate | 99.0635 | |
| buffer busy wait ratio | 0.2189 | |
| free buffer wait ratio | 0.0014 | |
| chained fetch ratio | 1.6892 | *** PCTFREE too low for a table |
| CPU parse overhead | 1.1423 | |
| cached cursor efficiency | 53.4631 | |
| parse/execute | 101.7552 | *** high parse rate |
| redo space wait ratio | 0.0000 | |
| disk sort ratio | 1.2517 | |
| rows from idx/total rows | 43.1392 | |
| short/total table scan ratio | 89.9202 | |
| blk changes per transctn | 11.4724 | |
| calls per transctn | 15.4401 | |
| commits/(commits+rollbacks) | 99.9807 | |
| rows per sort | 31.1387 | |
Buffer Cache Hit Ratio. This ratio describes the percentage of time a required data block was found in the buffer cache. For most applications, a value of at least 90 percent is desirable.
The buffer cache hit ratio is one of the most significant tuning ratios. Untuned values can lead to unnecessarily high disk I/O rates and contention for internal resources (latches). To improve the buffer cache hit ratio, you can increase the size of the buffer cache by increasing the size of the db_block_buffers configuration parameter.
Applications that perform frequent table scans of large tables may benefit little from increasing the buffer cache. For these applications, low buffer cache hit ratios may be unavoidable.
Library Cache Get Hit Ratio. The library cache get hit ratio describes
the frequency with which a matching SQL statement is found in the shared pool when
a SQL parse request is issued by a session. If a matching SQL statement is not found in
the library cache, the SQL statement must be parsed and loaded into the library cache.
Low hit rates will therefore result in high CPU consumption (from parsing) and
possible contention for library cache latches (when the new SQL is loaded into
the library cache). A acceptable rate for the library cache get hit rate is 90
to 95 percent or higher.
The most frequent cause of high miss rates in the
library cache is the use of literals rather than bind variables in SQL statements.
Bind variables reduce parse overhead by allowing otherwise identical SQL statements
with different query parameters to be matched in the shared pool. However,
bind variables preclude the use of column histograms and thus are not suitable in all
circumstances.
Library Cache Pin Hit Ratio. A library cache pin miss occurs when a session executes an SQL statement that it has already parsed but finds that the statement is no longer in the shared pool. This will occur if the statement has been "aged out" of the library cache to make way for new SQL statements. Expect a high ratio for the pin hit ratio because when parsed, an SQL statement should stay in the shared pool if it continues to be executed.
Low values (below 99 percent) for the library cache pin hit ratio usually imply that the shared pool is too small and that SQL statements are being aged out of the library cache prematurely.
Dictionary Cache Hit Rate. The dictionary cache contains information about the structures of database objects. This information is frequently accessed during SQL statement parsing and storage allocation.
The dictionary cache is stored in the shared pool and low hit rates (below 95 percent) probably indicate that the shared pool is too small. In this case, increase its size with the SHARED_POOL configuration parameter.
Latch Get Rates. Latches are Oracle internal locks that protect memory structures in the SGA. The latch get rate reflects the proportion of times requests for latches are satisfied without waiting. Latch hit rates should be high, usually over 99 percent.
Chained Fetch Ratio. This ratio represents the number of times sessions attempting to read a row had to perform an additional read because the row had been chained to another block. This will occur when an update to a row causes the row length to increase but there is insufficient free space in the block for the expanded row.
The typical cause of chained rows is an inadequate
value for PCTFREE, which is the amount of space within a block reserved for updates.
You can find tables that contain chained rows with the ANALYZE TABLE command, which
will store a count of the chained rows into the USER_TABLES view. Tables with chained
rows may need to be rebuilt using a higher value for PCTFREE.
Parse Ratios. The parse/execute ratio reflects the ratio of parse calls to execute calls. Because parsing is an expensive operation, statements should be parsed once and executed many times. High parse ratios (over 20 percent) may result from one of two circumstances: First, if literals rather than bind variables are used as query parameters, the SQL will need to be reparsed on every execution. (You should use bind variables whenever possible, unless there is a pressing reason for using column histograms.) Second, some development tools or techniques result in SQL cursors being discarded after execution. If a cursor is discarded, the parse will be required before the statement can be reexecuted.
If an application is discarding cursors,
it may be possible to relieve some of the parse overhead by creating a session
cursor cache. This task can be accomplished using the SESSION_CACHED_CURSORS
configuration parameter, which allows Oracle to maintain a "cache" of SQL statements
in the session memory. If a session requests a parse of a statement that it has
already parsed, it might be found in the cache and reparsing avoided.
The cached cursor efficiency ratio shows the efficiency of the session cursor cache. It reflects the percentage of times a parse request was satisfied from a SQL statement in the session cursor cache. If the parse ratio is high, but the cached cursor efficiency is low, the high parse rate is probably caused by a failure to use bind variables.
CPU Parse Overhead. The CPU parse overhead describes the proportion of CPU time consumed by server processes related to the parsing of SQL statements. If this ratio is low, reducing the parse ratio will probably not result in a significant performance boost. The higher the ratio, the more incentive you have to reducing parsing by using bind variables, reusing SQL cursors, or enabling a session cursor cache.
The CPU parse overhead can be low even if the parse ratio is high if the SQL being generated is very I/O intensive. In these circumstances, it may not matter that the statement is parsed every time.
Redo Space Wait Ratio. When a change is made to an Oracle data block,
an entry must be made to the redo log buffer. If there is insufficient space for
the redo log entry, a redo space wait will occur. The redo space wait records the
proportion of time a redo buffer had to wait because of insufficient space. If this
ratio is high--certainly if higher than 1 percent--the LOG_BUFFER parameter should
be increased.
Disk Sort Ratio.
This ratio records the proportion of Oracle sorts that were too large to be completed
in memory and that consequently involved sorting using a temporary segment.
Disk sorts are probably unavoidable if your application performs sort-merge joins,
aggregation, or ordering of large tables. However, if your application performs only
small sort operations, you can attempt to reduce the disk sort ratio by increasing
SORT_AREA_SIZE--but only if you have spare memory capacity on your server.
Next Time
In the next instalment, I'll wrap up the discussion of Oracle server monitoring and examine latch contention, session wait events, and some advanced techniques in detail.
Guy Harrison is an independent Oracle consultant specializing in Oracle
development and performance issues. This article was extracted from his book
Oracle SQL High-Performance Tuning (Prentice Hall, 1997). You can contact Guy
at [email protected] or at http://werple.net.au/~gharriso.
This is a copy of an article published @ http://www.oreview.com/