


Over the last couple of years, almost all conversations and articles on parallel databases have centered on the concept of data warehousing. The key points behind these discussions were speeding up (the ability to reduce the elapsed time in a query by adding more processing power for a given amount of data) and scaling up (the ability to perform a query in the same amount of time given that the data and processing power scale up in sync). This focus is not without reason, because the ability to siphon valuable information from large amounts of data gives corporations a significant competitive advantage over those that fail to do so. However, given the increasing use of applications by corporations, the large amount of data kept online, and the desire to run online transaction processing (OLTP) and decision-support workloads on the same system, the ability to scale OLTP applications in the open-systems environment is becoming more of an issue every day.
Database software has met the need to speed up and scale up by performing parallel execution of single SQL statements. It achieves this parallelism by splitting the SQL statement among a number of worker processes and by having each process work on a subset of the data. The results are then piped back to a coordinator process that communicates with the application. The coordinator processes and worker processes may be running in the same physical machine (in the case of an SMP environment) or on different physical machines (in the case of a clustered or MPP environment). Given the large amount of data processed in a data warehousing application, the benefits of running the query in parallel far outweigh the additional overhead. However, in an OLTP application, because each transaction is fairly simple and only reads or modifies a small amount of data, it is very important to make sure that the additional overhead required to provide parallelism does not actually outweigh the benefits provided by parallelism.
The three established parallel hardware platforms on which you can implement a database are shared memory (SMP), clustered (which can be shared disk or shared nothing), and shared nothing (MPP). (See Gordon Prioreschi�s February 1998 article, "Building on Bigger Boxes" in DBMS, for more information on parallel hardware platforms.) An SMP system is a computer with multiple processors that share common memory and disk. The operating system manages access to shared memory by the multiple processors to ensure that two processors do not write to the same address space at the same time. SMP systems are highly cost effective and can typically scale with the needs of most OLTP applications. However, the tightly coupled design will eventually result in contention for the shared resources; at this point you must turn to clusters and MPP systems for the next level of scalability.
A cluster environment is a collection of physical machines that, in most cases, communicate with each other over some private network. Each node in the cluster has its own processor (or processors in the case of clustered SMP machines) and memory, but all the nodes have access to a common set of disks for storage. If the disks within a cluster can be accessed by more than one node at a given time, the cluster is implementing a shared disk architecture. Clustered systems are used to improve performance by providing scalability outside of a single physical machine and improve the availability of important data. If one of the nodes in the cluster crashes, another node can pick up its workload because it has access to the same data.
An MPP environment is the same as a cluster environment except that the number of nodes is much larger. MPP machines have a scalable interconnect that allows them to scale to hundreds of nodes, while clusters have typically fewer than 10 nodes. Given the large number of nodes in an MPP environment, sharing disks is not possible. If a database requires a shared disk environment, it must be simulated through software.
The key difference in the hardware architectures from a database perspective is that an SMP environment only requires one instance of the database, so there is no communication among machines. However, a cluster or MPP environment requires an instance of the database on each physical machine, and coordinating transactions requires some type of communication among the different database instances. The type and amount of communication depends upon the architecture of the database (shared disk or shared nothing).
Data integrity within a database depends on two key concepts: concurrency and transaction atomicity. Database locking mechanisms allow multiple users to execute transactions within the database without compromising data integrity by ensuring that two different users are not allowed to update the same piece of data at the same time. Transaction atomicity ensures that all the individual steps that make up a transaction either complete successfully or are all backed out successfully.
Locking granularity plays a major role in the scalability characteristics of a parallel database, because multiple processors increase the contention for database resources. If the granularity of the locks is too coarse, applications will lock rows that they do not intend to access. This extra locking will prevent applications from scaling because increased processing power will only result in more users waiting while the resources they require are being locked by another user�s transaction. To maximize throughput (and thus scalability) you must have row-level locking, in which applications only lock those rows that they require for their transaction.
As a database scales beyond a single machine, it becomes more difficult to guarantee data integrity. A shared-disk database implementation (such as Oracle�s) must provide global locking because any instance of the database can update any piece of information. When a row is updated in an Oracle parallel server database, the transaction acquires an exclusive lock on the row, reads the data block into the instance�s buffer, and updates the row. However, the transaction also requires an additional lock to ensure that another instance does not try to update a different row in the same block of data at the same time. This distributed lock, known as a parallel cache management lock, is acquired at the block level and is held until another instance requests that block of data. The situation (shown in Figure 1) that arises when one instance writes out a block of data because it was requested by another instance is known as pinging. Pinging of data blocks between Oracle instances requires I/O, because blocks are written to disk by instance A before they can be read by instance B. This pinging can significantly decrease overall throughput. For this reason applications updating the same set of data will not scale if they access the data through different Oracle instances.
Distributed locking is not required in a shared-nothing database such as IBM DB2 Universal Database or Informix because each database instance only updates data residing on its own physical node. However, if a database transaction is initiated from database instance A, which updates data on database instance B, the database requires a more complex model for executing the transaction. This model will resemble the parallel query architecture I discussed at the beginning of the article. This type of transaction requires a coordinator process to manage the interface between the application and the database and a worker process to execute the update on database instance B. This model (shown in Figure 2) is required for all INSERTS, UPDATES, and DELETES where the target row resides on a different instance than the instance to which the application has connected. Because the amount of data access is very low, there is a significant overhead for this type of processing for typical OLTP transactions. Initial testing has shown that the time required to perform a single-row SELECT for a nonlocal row can be as much as 10 times the time required to process the same SELECT statement on a single-instance database. An important OLTP enhancement that DB2 Universal Database and Informix have implemented is the ability to eliminate the "coordinator process/worker process" architecture if the optimizer knows that the target row is located on the same instance as the application connection. This enhancement improves the performance of the same single-row SELECT to the same level as that obtained on a single instance database.
Performing an UPDATE across several different database instances requires all the previously mentioned coordinator process/worker process overhead and adds the requirement of a two-phase commit protocol to guarantee that the data has been successfully committed on all participating nodes. Once again, the overhead compared to performing an UPDATE on a single machine is substantial.
The database must be very efficient in processing individual transactions to achieve the greatest possible throughput. For example, an OLTP workload typically involves a very large number of users. You could have a separate process (or thread) dedicated to each user, but this leads to a high number of processes, and managing all these processes can strain your system. Instead, you can take advantage of the fact that each user is generally executing short, simple transactions. At any given point in time, most of the users will be between transactions (this is referred to as "think time") and will therefore be idle. Only a small percentage (for example, 10 percent) will be active at any given time. This means that instead of having a process for each user, you can create a much smaller pool of processes (again, maybe only 10 percent of the number of connected users) that are shared between all the users. When a user submits a transaction, the next available process from the process pool is used to execute that transaction. This strategy reduces contention because there are fewer concurrently active processes. In fact, somewhat counter-intuitively, the actual overall throughput of the system can be increased by limiting the number of users that can concurrently execute a transaction. If the database cannot provide this capability, you can use a transaction processing (TP) monitor to perform user scheduling and improve overall throughput.
Throughput in an OLTP system is often limited by I/O bottlenecks, which are usually the result of a large number of requests searching for small amounts of data rather than large serial I/O requests. You can alleviate these bottlenecks by adding more drives and spreading out the data to minimize seeking. A typical scenario is to place index and data blocks on separate devices. This guarantees that a typical OLTP read operation (performing I/O to get row ID followed by an I/O to get data from the row) will not cause the disk head to jump back and forth between the index and the data blocks.
You can increase scalability further if you reduce the number of I/O operations by caching frequently accessed data. If the database supports multiple buffer pools, frequently accessed data (such as an important index) can be placed in its own buffer pool. If the buffer pool is large enough, the index can remain in memory and all the I/O operations on the index can be eliminated.
Eliminating these bottlenecks will enable your applications to scale on SMP platforms until, eventually, the only bottleneck is memory access. At this point you scale by adding another physical machine (or machines) with its own memory and disk. But given the additional effort required to ensure integrity as a database shifts from a single physical machine to multiple machines, linear scalability does not seem realistic. However, if the database is not required to ping data blocks back and forth (in the case of a shared-disk database) or use the "coordinator process/worker process" architecture to access nonlocal rows, OLTP workloads will scale as additional nodes are added to the system. The procedure to minimize pinging or the access or nonlocal rows is often referred to as application partitioning.
Application partitioning is achieved in a shared-disk database such as Oracle by ensuring that specific database instances update certain subsets of the data. You can do this in Oracle8 by using the new features for partitioning tables and configuring the application to route transactions to specific Oracle instances. A simple example could be an Oracle database with two instances being used by a company with 100 stores. If the transaction table is partitioned by STORE_NUMBER to place data for the first 50 stores in tablespace A and the second 50 stores in tablespace B, you partition the application by connecting the point-of-sale applications for stores 1 to 50 to instance A and connecting the point-of-sale applications for stores 51 to 100 to instance B. Instance 1 would never have to update a block of data in tablespace B and instance 2 would never have to update a block in tablespace A; data blocks would not be pinged back and forth.
In a shared-nothing database where data partitioning is a requirement (such as DB2 Universal Database or Informix), the application is partitioned to avoid the "coordinator process/worker process" overhead and the cost of performing a two-phase commit. The goal of application partitioning in this environment would be to guarantee that only one node is updated in a transaction and that the application connects to the node being updated. If this goal is achieved, the OLTP application will scale as more nodes are added to the system.
I implemented application partitioning using a shared-nothing database at a telecommunications company in order to scale the call information being fed in from the telephone switches. The primary requirement of the database system was to support a combined DSS and OLTP workload while ensuring that the calls occurring over the telephone switches were collected in real time. This system was implemented using DB2 Parallel Edition and the IBM SP platform.
The database was created over 16 physical nodes with 10 nodes dedicated to the decision-support system (DSS) and six nodes dedicated to receiving telephone-call information from the telephone switches. At specified intervals the OLTP data was copied from the transactional tables to DSS tables for analysis. This process kept the OLTP and DSS applications separate, although they both accessed the same database. The call_data table was partitioned by a switch ID number to ensure that data from a given switch always ended up on the same nodes and to balance the workload between the OLTP nodes. This partitioning also allowed the switch applications to connect directly to the OLTP nodes where their call data would be inserted. The partitioning thus provided a linearly scalable OLTP application. As the number of calls increases and new switches are added, the database can scale with the increased data by adding more OLTP nodes to the system.
Application partitioning was straightforward in this case because the insertion of call data did not rely on accessing any other tables to perform the insert transaction. Another common requirement in OLTP applications is accessing a small lookup table to verify information before inserting or updating a record. To scale an OLTP application of this type with a shared-nothing database, the lookup table must be partitioned in the same way as the transaction table to allow lookups to be performed without having to access data stored on another node. This may require adding a partitioning column to the lookup table and replicating its contents on every node. These modifications to ensure scalability may change the logical design and the SQL required to access the tables.
For databases to become scalable for OLTP in the MPP environment, they must be able to replicate small lookup tables to all the database instances. This functionality will remove the requirements of modifying the database design in order to replicate a table. The optimizer will be able to recognize a replicated table and thus be able to satisfy many OLTP transactions without having to access data residing on a database instance other than the one to which the database is connected.
You can also achieve application partitioning in a three-tier environment by using the middle tier to route transactions based upon database partitioning keys. This functionality has already been incorporated into some TP monitors such as CICS and Encina.
The information stored in OLTP systems is critical to the day-to-day operation of most companies. Databases must therefore provide the ability to take backups of the system to make sure that important data is not permanently corrupt or lost because of a system or application error. OLTP systems are almost always changing, so database backups must be taken regularly to reduce recovering time if a serious error occurs. However, because many companies require 24 3 7 or near 24 3 7 access to their OLTP systems, there may not be a window of opportunity in which to perform a full backup of the system. In this case several different options are available to reduce backup time. Some of the options are:
Backing up a subset of the database is analogous to performing a tablespace or table-level backup. The benefit of this approach is that you don�t need additional hardware to meet a given backup window. The main drawback is that during a database restore, some subsets of the database may not have had a recent backup and you may have to do a large amount of log processing to bring that subset of the data back to a consistent state just before the time of failure.
Parallel backup typically refers to backing up different subsets (such as a tablespace) of a database in parallel to different storage devices. This operation is highly scalable because the source data is read off separate physical devices and the backup is written to separate devices. Some databases such as DB2 Universal Database even support parallel backup within a tablespace. This strategy will split the backup of a single tablespace between different storage devices. Although this approach may not decrease the time necessary to take a full backup (the time will depend upon the number of backup devices), it will substantially reduce the time required to restore that tablespace. The main drawback of parallel backup and restore is that you must have additional tape drives or disks. Performing parallel backups can also result in numerous backup files that you must manage, so for large database environments I recommend that you automate the backup storage with some type of storage-management product.
Incremental backups take less time because they only copy the data that has been changed since the last backup. The disadvantage is that multiple backup files must be managed and multiple backups must be restored before applying the logs.
You can perform an online backup while users are accessing and updating the data. To restore a database from an online backup, you must apply log files to bring the database to a consistent state after the restore has taken place. The main benefit of an online backup is that it may occur while the database is available for access and thus a backup window is not explicitly required. In a large database environment, you can combine several backup strategies, such as performing an online backup of multiple partitions in parallel.
Scalable cluster and MPP platforms, along with fault-tolerant hardware such as RAID or disk mirroring, provide an attractive environment for implementing a highly available database. Databases such as DB2 Universal Database, Informix, and Oracle provide the ability to shift the database workload from a failed physical node to a surviving node to ensure that the database is always available for use, even in the case of a hardware failure. With version 8, Oracle has taken this one step forward to provide application failover, which will reconnect an application with a surviving node, allowing it to continue working without having to reconnect.
The ability to execute DSS and OLTP applications on the same platform is very appealing to corporations. By removing the complexity of transferring data among different operational and informational systems, you effectively reduce implementation costs. Furthermore, you gain a competitive advantage by being able to transform operational data into strategic information more rapidly than your competitors. By understanding how OLTP transactions are executed in a parallel database and by implementing some level of application partitioning, you can now implement OLTP applications in the same cluster as those MPP environments in which DSS applications reside.
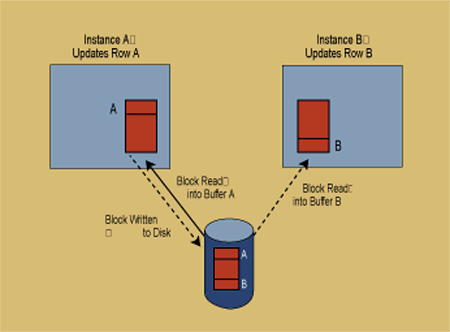
Figure 1. Block pinging in a shared-disk database.
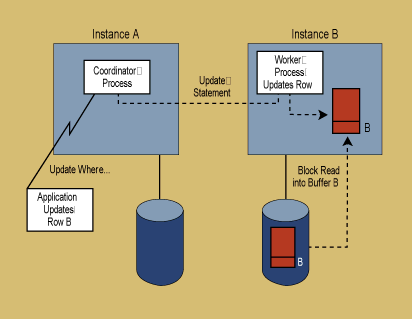
Figure 2. Updating a remote row in a shared-nothing database.