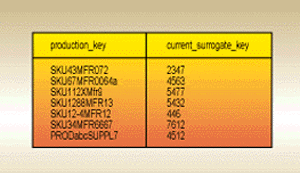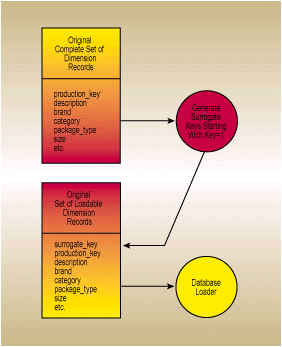
Figure 1. The original loading of a dimension. Surrogate keys are just assigned sequentially to every input record. The original production key becomes an ordinary attribute.

Last month I tried to convince you to use surrogate keys for every join in your dimensional data warehouse. In other words, every join key between a fact table and a dimension table would be a surrogate or anonymous integer, not a natural key or a smart key. You should make the anonymous surrogate key by assigning 1 to the first instance of the key, 2 to the second instance of the key, and so on. It is impossible to tell anything about the value or the context of the dimension records by looking only at the surrogate key values. All surrogate keys end up as four-byte integers (and sometimes even two-byte integers for tiny dimensions) because a four-byte integer is capable of representing at least two billion possible dimension records. I�ve never in my career heard of a single dimension with as many as two billion records.
In last month�s column, I pointed out that surrogate keys allow the data warehouse administrator the freedom to represent slowly changing dimensions, as well as unknown, uncertain, or not-yet-recorded dimension values. Finally, the use of surrogate keys restores administrative control to the data warehouse owner by insulating the warehouse from unexpected changes in the production system.
Once you have created the dimension records with the right surrogate keys, any fact table that references these dimensions must be appointed with the right surrogate key values. In this case, the surrogate key in the fact table is a foreign key, which means that the value of the surrogate key exists in the corresponding dimension table. Think of the dimension table as the "key master" for the dimension. The dimension table controls whether the surrogate key is valid because the surrogate key is the primary key in the dimension table.
When every surrogate key in the fact table is a proper foreign key connecting to its respective primary key in one of the dimension tables, the fact table and the dimension tables obey referential integrity. Fact tables with four and 12 foreign keys connecting outward to a halo of dimension tables present an interesting challenge during data extraction: You must intercept all the incoming fact records and replace all their key components with the correct surrogate key values at high speed.
Let�s tackle the challenge of creating the primary surrogate keys in the dimension tables first and then deal with fast fact table key generation.
When we think about creating the keys for dimension tables, we can distinguish the dimension table�s original load from all subsequent loads. The original load probably creates a dimension table with exactly the same number of records as the incoming production data. Assume that the incoming production data is clean and valid and no further "de-duplicating" of the incoming data is needed. Given this assumption, simply assign sequential numbers for the surrogate key as you load the dimension for the very first time. This simple process is just a sequential read of the incoming data, as shown in Figure 1.
Things get much more interesting after the dimension�s original load. The second, and any subsequent, time you read the production data defining the dimension, you must make some complicated decisions. The easiest decision is to recognize new records that have been added to the dimension in the production system and assigned new production keys. For simplicity�s sake, imagine that the production data has a clean, well-maintained single field called the production key. (This discussion doesn�t really change if the uniqueness of a production dimension record is defined by several separate fields.) Each time you extract the production dimension information, you must check all the production keys to see if you�ve encountered them before. Conceptually, you could just look in the data warehouse dimension table where the production key is stored as an ordinary field. Momentarily, however, I will recommend a separate lookup table for this purpose, rather than using the real data warehouse dimension table.
When reading the incoming production data that defines the dimension, a more difficult decision comes if you�ve seen the production key before but some other attributes in the dimension record have been legitimately changed. This is the classic slowly changing dimension situation; for example, a product might have a minor change in its packaging or ingredients, but the underlying SKU number (the production key) hasn�t been changed, or a customer keeps the same Customer ID, but some description, such as marital status, has changed. To resolve these problems, you must have a slowly changing dimension policy. This policy says that if certain descriptive fields in a dimension change, the data in the record is destructively overwritten (the so-called Type 1 change). But if other descriptive fields, such as the customer�s marital status, change, a new data warehouse dimension record is issued (the Type 2 change). The policy identifies which fields are overwritten or reissued, and the policy is implemented in the transformation logic of the data warehouse extract pipeline.
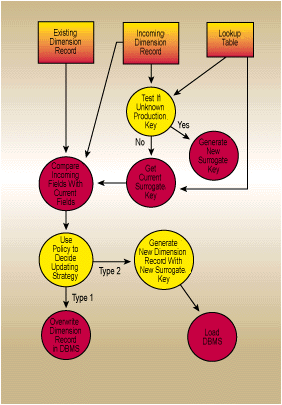
The fastest way to decide if you�ve seen an incoming production key before is to have a special table of previously recognized production keys, preferably sorted and indexed for the fastest possible reference. (See Figure 2.) This table has fewer rows than the data warehouse dimension table because it only has one row for each recognized production key. Along with the production key, the lookup table contains the most recent surrogate key used with this production key.
Each morning as the incoming production data for the dimension is processed, use the lookup table to decide whether you have seen each production key before. If you haven�t seen the production key, then you immediately know you must create a new data warehouse dimension record. If you keep track of the highest surrogate key value previously used in this dimension, you can just add "one" to this value, creating the new dimension record. Conversely, if you�ve seen the production key before, then grab the surrogate key from the lookup table and use it to get the most current value of the data warehouse dimension record. Then compare the current data warehouse version with the incoming production version of the record, field by field. If everything matches, then you don�t have a slowly changing record, and can go on to the next record in the input. If one or more fields have been changed, use your slowly changing dimension policy to decide whether to overwrite or create a new record. If you create a new record, then you must change the lookup table, because now you have a more recent surrogate key that represents your production key. (See Figure 3.)
If you�re lucky enough to have production data for which the changes have been marked and timestamped, then you can avoid the fairly expensive field-by-field comparison step I just described. However, the rest of the logic probably remains unchanged.
An interesting advanced design technique for handling Type 2 slowly changing dimensions is to have three fields in the data warehouse dimension table in addition to the surrogate key field needed for the basic processing. These fields are Effective Date/Time, Next Change Date/Time, and Effective Transaction. These fields allow some very powerful slices to be made through the dimension table, representing any instant in time over the dimension table�s whole history. I discussed the use of these fields at length in my February 1998 column on Human Resources Data Marts.
You must process the dimension tables before you even think of dealing with the fact tables. When you�re finished updating your dimension tables, not only are all the dimension records correct, but your lookup tables that tie the production keys to the current values of the data warehouse keys have been updated correctly. These little lookup tables are essential for fast fact table processing.
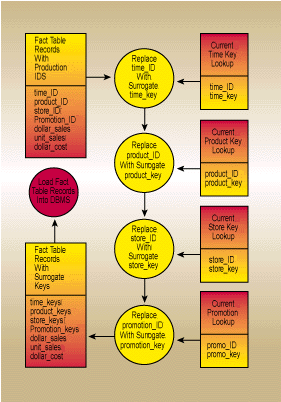
Your task for processing the incoming fact table records is simple to understand. Grab each production dimension key in the fact table record and replace it with the correct current surrogate key. Notice that I said "replace." Don�t keep the production key value in the fact record itself. If you care what the production key value is, you can always find it in the associated dimension record.
If you have between four and 12 production keys, then every incoming fact record requires between four and 12 separate lookups to get the right surrogate keys. Figure 4 shows my favorite way to do this quickly. First set up a multithreaded application that streams all the input records through all the steps shown in Figure 4. When I say multithreaded, I mean that as input record #1 is running the gauntlet of successive key lookups and replacements, record #2 is simultaneously behind record #1, and so on. We do not process all the incoming records in the first lookup step and then pass the whole file to the next step. For fast performance, it is essential that the input records are not written to disk until they have passed though all the processing steps. They must "fly" through memory without touching ground (the disk) until the end.
If possible, all the required lookup tables should be pinned in memory so that they can be randomly accessed as each incoming fact record presents its production keys. This is one of the reasons for making the lookup tables separate from the original data warehouse dimension tables. Suppose you have a million-row lookup table for a dimension. If the production key is 20 bytes and the surrogate key is four bytes, then you need roughly 24MB of RAM to hold the lookup table. In an environment where you can configure the data staging machine with 256MB of RAM or more, you may be able to get all the lookup tables in memory.
In some important large fact tables, you may have a "monster dimension," such as residential customer, that numbers in the tens of millions. If we only have one such huge dimension, you can still design a fast pipelined surrogate key system, even though the huge dimension lookup table must be read off the disk as it is being used. The secret is to presort both the incoming fact data and the lookup table on the production key. Now the surrogate key replacement is a single pass sort-merge through the two files. This should be pretty fast, although nothing beats in-memory processing. If you have two such monster lookup tables in your pipeline, then you need a consultant!
Although the design of a good fast surrogate key system obviously takes a little thought, you will reap many useful benefits. A good surrogate key system will reduce space in the big expensive fact table, eliminate administrative surprises coming from production, potentially adapt to big surprises like a merger or an acquisition, have a flexible mechanism for handling slowly changing dimensions, and represent legitimate states of uncertainty for which no natural keys exist.
Figure 1. The original loading of a dimension. Surrogate keys are just assigned sequentially to every input record. The original production key becomes an ordinary attribute.