![]()
By Roger Snowden
OReview, March 1997
Roger continues his exploration of application tuning in Part 2 of this three-part series.
In Part 1 of this series, I discussed how application tuning is an integral part of the overall client/server performance tuning process. Moreover, it is a cooperative process that requires effort from application developers as well as DBAs. I've heard it suggested that application tuning can account for 80 percent of potential performance gains in a client/server system far greater than the gains to be expected from tuning the database engine itself. This suggests that application tuning is a large subject, yet surprisingly little has been written about it. Conversely, a great deal of material is available on the subject of fine-tuning relational database engines.
Application tuning is too broad a subject to cover exhaustively on these pages, but in this series of articles I have attempted to at least identify the key issues associated with the process and suggest some techniques for approaching the subject. Perhaps other database administrators and developers will contribute their thoughts and from this community a coherent methodology will eventually emerge.
In Part 1, I explored the importance of bind variables, managing Oracle7's shared pool with its library cache. I briefly outlined the SQL_TRACE facility and EXPLAIN PLAN and covered the issue of index selectivity, including the Oracle utilities for tuning indexes. I covered some of the issues related to Oracle's optimization technology and introduced optimizer hints. I also briefly touched on Oracle's Parallel Query Option. In Part 2, I continue my exploration of application tuning. I lightly touch on the subject of SQL statement optimization. I also visit the issues of application partitioning with server-based logic and index techniques, and I discuss the ever-controversial matter of ODBC.
Tuning SQL
A lot of literature describes how to write optimal SQL, so I won't belabor
the issue here. A few points are worth noting, however:
Simplify as much as possible and enrich judiciously. Overly complex SQL statements can overwhelm an optimizer. Pay special attention to the EXPLAIN PLAN cost estimate. Cost, in Oracle, is a relative concept. Nobody seems to know exactly what the "cost" numeric value means. But in general smaller is better, so compare one statement's cost to another.
When appropriate, use the special extensions to the Oracle database. "Oraclisms" can save you time, both in development and at runtime. These special extensions exist to provide you with an advantage, and what Oracle does for itself in its own space, it does very well. The MINUS operator, for example, can be much faster than using WHERE NOT EXISTS or WHERE NOT IN (SELECT). The UNION operator, which is standard SQL and not peculiar to Oracle, is also a potential shortcut, especially for a self-join with two noncontiguous index range values.
Following is an example of the power of the MINUS operator versus the NOT IN construct. First, the NOT IN approach:
SELECT customer_id FROM customers WHERE area_code IN (402, 310) AND zip_code NOT IN (68116, 68106);
Even if we have indexes on both the AREA_CODE and ZIP_CODE columns, the NOT IN predicate, to eliminate two zip codes from the result set, will necessitate a full table scan. On the other hand:
SELECT customer_id
FROM customers
WHERE area_code IN (402, 310)
MINUS
(SELECT customer_id
FROM customers
WHERE zip_code IN (68116, 68106);
With both AREA_CODE and ZIP_CODE as the left-most columns in separate indexes, Oracle can use the ZIP_CODE column to get just those two zip codes I wish to eliminate and simply subtract them from my result set. No full table scan is necessary. In a large table, this approach really pays off. Doesn't this version even look intuitive? This is one extension of Oracle that truly belongs in the ANSI standard.
Following is an example of the UNION operator retrieving two noncontiguous result sets in a similar business situation:
SELECT customer_id FROM customer WHERE area_code IN (402, 310) UNION SELECT customer_id FROM customers WHERE zip_code IN (31326, 31327);
Bear in mind that this only helps if the AREA_CODE and ZIP_CODE columns are left-most in the indexes. As mentioned, this is standard SQL - no "Oraclism" here - but this technique is often overlooked.
Be careful with SQL and PL/SQL functions. Although you can embed SQL functions as well as PL/SQL custom and intrinsic functions in SQL, enclosing an indexed column in a function will force a full table scan every time. For example:
SELECT account FROM vendors WHERE UPPER(vendor_name) LIKE 'SMITH%';
Use of the UPPER SQL function completely obviates the partial-key search indicated by the LIKE operator, resulting in a full table scan.
Take advantage of ROWNUM. ROWNUM is a special pseudo-column that exists for every result set. It is quite useful for limiting a potential runaway query and avoiding application grief. It refers to the relative row for a given query, before any ORDER BY clause is applied. This is important to understand. If your statement looks like:
SELECT COUNT(*) FROM customers WHERE ROWNUM < 100
Oracle will select and return the first 99 rows and the query will halt. If you have a name search on a large table, selecting WHERE NAME LIKE S% could easily return 100,000 rows or more. Rather than forcing your users to logically qualify the query, you can add this row-limit qualifier to end the search when the upper limit is reached:
SELECT name, address, city FROM customers WHERE name LIKE 'S%' AND ROWNUM < 1000
will return no more than 999 rows. More important, the query will return when the upper limit is reached, before executing any sorts. This is a wonderful saving grace that you should use more often.
Enable your users to cancel queries. This issue is perhaps less obvious. When processing multirow queries, many client tools are able to display rows as they are returned. If a user finds the desired row on the first page, he or she can cancel the query, rather waiting for the entire result set. This can save considerable network traffic and database I/O at the minor expense of more intelligent client code.
Use declarative integrity constraints where appropriate. Enforcing referential integrity through an application is expensive. You can maintain a foreign-key reference by selecting the column value of the child from the parent and ensuring that it exists, but the foreign-key constraint enforcement supplied by Oracle does not use SQL, is much faster, is simple to declare, and doesn't create network traffic.
When possible, use array processing. Some client tools let you use array processing, whereby an array of bind variable values is passed to Oracle for repeated execution. This is appropriate for iterative processes in which multiple rows of a set are subject to the same operation. This can save multiple trips to the database and significant time at the client workstation. This feature is not universally available for client tools, so check with your own vendor for specifics.
Application Partitioning
Application partitioning refers to the process of distributing the program
workload between the client and the server, typically by using server-based
logic. The initial idea behind the client/server architecture was to offload
work from a centralized host processor. That was in the pre-1990s days of
the monolithic host-based, process-driven application minicomputers and
mainframes.
The technology that became client/server involved techniques that were relatively simple and straightforward. Before relational databases became servers that responded to SQL messages, you wrote a conventional program that worked on a microprocessor, and it communicated with the host-based file system. The job of that early server was to send and receive data to and from the client, or requester. Data was stored in the form of ISAM, or indexed sequential files, because SQL engines were not yet available. This was the embryonic phase of client/server. All application logic resided on the client; most developers were simply glad to relieve the host of the chore of moving cursors around and processing keystrokes.
Now it's different. Networks cross multiple states and servers are quite powerful. Applications scale to hundreds of users and network traffic is heavy at times. Moving many rows of data to the client for processing is not as simple as it was back in the lab. The obvious solution is to move some of the application logic back to the server or to an intermediate machine closer to the server. This usually involves the implementation of server-based logic, or stored procedures.
The problem with application partitioning is that for most systems, the language on the client is not the same as the language on the server. With Oracle's Developer/2000 product, the language is the same: PL/SQL. But if you have a three-tier system, you might use C or C++ on the client and the application server in the middle. For most systems, you must write in two or more languages.
Partitioning the application between the client and the server lets you avoid network traffic. For cases in which you have many rows selected and relatively little data eventually needed at the client, consider using server-based logic. You can implement this logic in the form of stored procedures or triggers. Triggers are pieces of logic that execute as the result of some event, often the insertion of a row into a particular table. Stored procedures are either procedures or functions that are called discretely by the client program or from within a trigger or another stored procedure. Oracle7 supports stored functions as well as stored procedures.
Because functions return values, their power becomes apparent when you realize that they can be embedded directly in a SQL statement. Think about the power of that idea: A single function, embedded in a SQL statement, can encapsulate huge chunks of logic that execute inside the Oracle engine. Many rows of data can be processed, returning perhaps a single piece of data over the network. You get big processing power with very little network traffic. It is a good tool for making use of today's incredibly powerful servers. Such technology begins to make up for the fact that network speeds are really no better than they were 10 years ago.
Oracle has a library of intrinsic functions that can be embedded in SQL. Actually, those functions are part of the PL/SQL library and were documented in the PL/SQL User's Guide and Reference. Now they are included in the Oracle7 Server SQL Reference Manual. What is especially important is that you can write your own functions in PL/SQL and extend that library with your own customizations. Powerful stuff. You can even overcome some of the limitations of ODBC with embedded PL/SQL. Although you cannot call stored functions and procedures directly with ODBC and get return values, you can create a fake SQL statement with DUAL (a dummy table in Oracle7) that will execute your stored function and return it as a result set. This only works for functions, not procedures, and you can only return a scalar value with it; arrays do not work here.
Many application programmers are intimidated by PL/SQL. It may help to understand that PL/SQL is a subset of Ada, which in turn is derived from Pascal. It is a clean, block-structured language that is strongly typed. If you studied Pascal or used Turbo-Pascal or Delphi, PL/SQL should be very familiar. C programmers normally do not have a problem adapting to it. PL/SQL has a great deal of flexibility and power and even supports polymorphism with its function overloading. Although the PL/SQL documentation is neither a good tutorial nor an adequate reference, there are a couple of excellent third-party books on the subject: Oracle PL/SQL Programming by Steve Feuerstein (O'Reilly & Associates, 1994) and Oracle PL/SQL Programming by Scott Urman (Oracle Press, 1996). If you seriously intend to get performance from Oracle, you need to know PL/SQL.
In any case, regardless of whether you use procedures or functions as vehicles for server-based logic, you should make decisions about application partitioning early. Retrofitting logic in a client/server system means rewriting the code. Unless you are using Developer/2000 (with which moving logic between the client and the server is a drag-and-drop affair), careful planning is in order, which is in conflict with today's environment of quick-and-dirty prototyping and rapid application development methodologies. Nevertheless, if you put your application together with all of the logic on the client, you may pay a serious price when you try to scale the system to production. In spite of our marvelous development tools, the order of the day is still design.
When considering how to partition, look for places in your application at which many rows are treated and relatively little data is needed at the client perhaps a true/false condition based on some complex join. Even reports, although they do not normally belong in high-volume transaction-processing environments, may be good candidates for placement on the server. Rather than transporting data to the server for formatting and then sending it back over the network in the form of report text, you might have the server produce the text and send the output once directly to the spooler or printer.
When placing logic on the server, be careful to avoid overkill. Stored procedures and functions are not free. During a recent consulting engagement, a client was convinced that all SQL should be placed within stored procedures and accessed via stored procedure calls from the client. I felt this was a bit extreme, so I conducted a simple test using dynamic SQL and a PL/SQL wrapper. The test measured the difference between sending a SQL statement directly to Oracle and calling a stored procedure that executes the same SQL statement. The direct, pure SQL statement was about 10 percent faster, indicating measurable overhead in the procedure call. Not a big difference, but one that could matter in some cases and is worth noting.
Index Techniques: Avoiding Input/Output
Another area that can be tuned to improve query performance is selecting
on index columns alone. That is, the columns requested in the SELECT statement
are entirely contained within one or more indexes. When such a query executes,
Oracle can return the result set without even touching the rows themselves.
Consider Figure 1. In this example (albeit a trivial
one), you can retrieve the names for all customers within the specified
range of phone numbers without actually accessing the table. All of the
data is contained within the alternate index. This works whether the index
is unique or not. Be sure to test your own query with the EXPLAIN PLAN utility,
discussed in Part 1 of this series (January/February,
page 10). Also, note that an optimal statement execution plan might
not be clear to Oracle's optimizer when you create many similar but different
indexes for a table.
You can also combine indexes to minimize row fetches. Consider another example involving a self-join for which you want to select on a telephone area code and a zip code. The table in Figure 2 has two alternate indexes in addition to a primary key. One alternate index consists of the concatenation of the AREA_CODE and EXCHANGE columns. The other alternate index is on the ZIP_CODE column. When Oracle's optimizer analyzes the SELECT statement, it sees an AND-EQUAL condition. That is, the optimizer determines that both elements of the WHERE clause use equality operators and both use indexes. Normally, the database would fetch the rows associated with each index and combine them afterward. In this case, Oracle will combine the results from two indexes before fetching rows, which may well result in fewer row fetches than would happen if the results were combined after the fetching.
Portability That Holiest of Grails
Now that I have discussed the use of Oracle-specific extensions to SQL,
you might argue that such SQL is not portable. You would be correct. I would
suggest, however, that the notion of portability in the database world is
truly overblown and mostly irrelevant. If build your applications on Oracle,
you are committed to Oracle or you are wasting resources. Every database
engine on the market today uses some proprietary language for server-based
logic. For Oracle, the language is PL/SQL. If you want portability, you
cannot use PL/SQL because nobody else supports it. On the other hand, if
you want performance, you will have to use some amount of server-based logic,
either in stored procedures or triggers. Until the ANSI Committee saves
us from ourselves, portability across relational database systems will remain
difficult or impossible. You can achieve portability at the design level,
but sooner or later the implementation will come down to code. Even if your
organization does consider switching database vendors, that vendor's proprietary
features will probably drive the deal anyway.
ODBC
Open database connectivity has been surrounded by controversy since Microsoft
Corp. introduced it. In spite of the misunderstandings, ODBC works and is
overwhelmingly common. It is not without problems, however, especially in
large-scale environments. It is often accused of being slow, but its presumed
slowness results mostly from its association with Microsoft Access. When
users connect to Oracle with ODBC, they often go through Access, which acts
as an intermediary navigation tool, discovering tables, columns, and datatypes
and generally making life simpler for the casual user. This process creates
overhead, however, and slows response time dramatically. ODBC often gets
the blame, although tests show that ODBC returns data directly from the
database at about the same speed as the Oracle Call Interface (OCI), Oracle's
proprietary interface.
ODBC is not blameless, however it does have its limitations. With release 7.2, Oracle supports a cursor datatype and, with the correct interface, is able to return result sets via stored procedures. ODBC is perfectly capable of calling stored procedures, but it does not support the cursor datatype required to obtain a result set. Additionally, Oracle stored procedures and functions are able to return discrete data values through return parameters. Unfortunately, ODBC does not support the returning of values through parameters. ODBC does a fine job with straightforward, generic SQL. If you genuinely intend to have portability, though, ODBC may be your best bet. But without stored procedures, large-scale applications are limited in their performance potential. More often than not, it comes down to either a political or business decision.
The bottom line is this: If ODBC is not being crammed down your throat and you're dealing with a large-scale application, consider the tradeoff between portability and performance carefully. Some new tools implement OCI through the OCX mechanism and may simplify the use of a proprietary interface. You may be able to design your application so that stored procedures do not have to return values to the client. Or you might conclude that the convenience and performance options delivered by so-called proprietary interfaces are worth whatever coding hassles are involved in changing database engines, should you actually decide to abandon your DBMS vendor.
Wrapping Up and Rounding Out
The subject of application tuning covers a lot of ground. I've only touched
on some of the compromises involved in the optimization of client/server
performance. Each application must be tuned within the context of its own
environment, and no two systems are alike.
The most important step in getting client/server systems to perform is the first: design. The most responsive and effective systems always seem be those that have performance designed in from the beginning. Next month, I will discuss design and architectural issues, including transaction management and locking strategies. I'll close up this discussion with a brief look at application architecture and design considerations, and I'll explore some of the issues surrounding scalability of applications with respect to performance.
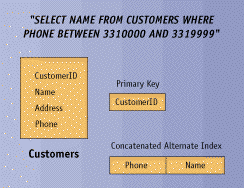
Figure 2. When Oracle's optimizer analyzes the SELECT statement shown here, it sees an AND-EQUAL condition. That is, the optimizer determines that both elements of the WHERE clause use equality operators and both use indexes. Normally, the database would fetch the rows associated with each index and combine them afterward. In this case, Oracle will combine the results from two indexes before fetching rows, which may well result in fewer row fetches than would happen if the results were combined after the fetching.
